Elements de supervision vmware
Introduction sur mon besoin et les outils retenus
Mon petit lab personnel s’exécutant sous vmware, si je voulais aller au bout de la supervision de mon cluster Kubernetes, je me devais également de surveiller la partie hyperviseur.
J’ai donc cherché à capitaliser sur mes découvertes autour de grafana issue de mon article précédent pour inclure un monitoring vmware un peu différent de ce à quoi j’avais l’habitude (vROPS, Zabbix..)
Je suis donc tombé sur différents petits tutoriels (notamment celui-ci) qui m’ont permis la mise en œuvre de dashboards pouvant se montrer intéressant en cumulant grafana, influxdb et telegraf.
Encore une fois, le but de cette article n'est pas de détailler l'usage et l'installation de ces produits, mais simplement de d'évoquer leur mise en oeuvre.
Mise en oeuvre
InfluxDB
Je débute par influxdb. C’est une base de données orientée « time series », donc particulièrement adaptée au stockage de métriques de supervision.
Son installation est très simple puisque la plupart des distributions l’intègrent dans ses repository.
update 14/06/2020:
Attention à ceux qui comme moi utiliseraient Ubuntu 20.04. La version d'InfluxDB présente dans les repos officiel canonical est trop ancienne pour fonctionner correctement avec les dashboards grafana présentés plus tard dans l'article. Il faut donc utiliser le repo de l'éditeur "https://repos.influxdata.com/ubuntu/dists/eoan/", pas celui de "focal" car même si celui-ci correspond à la version d'Ubuntu 20.04, il ne contient pas de binaire pour InfluxDB.
(Je l’ai personnellement installé sur mon serveur de supervision, une VM sous "Ubuntu 20.04" avec le paramétrage par défaut.)
Je crée une database qui va me servir à stocker les données issues de l’interrogation de l’API vCenter.
influx -execute “CREATE DATABASE sup_database WITH DURATION 30d”
Je configure uniquement une rétention de 30J, ce qui est amplement suffisant pour mon usage.
Je crée un utilisateur spécifique que j’associe à cette base
influx -execute "CREATE USER sup_user WITH PASSWORD 'mon_password'"
J’associe cet utilisateur à ma base
influx -execute "GRANT ALL ON sup_database TO sup_user”
Telegraf
Ma base est prête, il ne me reste plus qu’à l'alimenter.
Pour cela je vais utiliser telegraf
C’est un agent capable d’interroger beaucoup de métriques distantes ou locales afin de les renvoyer vers différentes destinations, en l’occurrence ici vers une base influxdb.
L’installation de telegraf n’est pas complexe, mais peut nécessiter comme sous Ubuntu d’ajouter des repos complémentaires à sa distribution. Tout est très bien expliqué dans la doc officielle
Les versions récentes de telegraf intègrent un plugin pour vmware sur lequel je vais pouvoir m'appuyer pour interroger mon vCenter.
La communauté amenant son lot d’avantage, des dashboards déjà préconfigurés pour grafana et basés sur une source influxdb alimentée par un agent telegraf sont disponible à ces adresses :
https://grafana.com/grafana/dashboards/8165
https://grafana.com/grafana/dashboards/8159
https://grafana.com/grafana/dashboards/8162
https://grafana.com/grafana/dashboards/8168
L’auteur indique directement la configuration telegraf à implémenter. Dans mon cas, j’exploite le fichier suivant
[[outputs.influxdb]]
urls = ["http://127.0.0.1:8086"]
database = "{{ influxdb_database_name }}"
timeout = "0s"
username = "{{ influx_user }}"
password = "{{ influx_password }}"
## Realtime instance
[[inputs.vsphere]]
## List of vCenter URLs to be monitored. These three lines must be uncommented
## and edited for the plugin to work.
interval = "20s"
vcenters = [ "https://{{ vcenter }}/sdk" ]
username = "{{ vcenter_username }}"
password = "{{ vcenter_password }}"
vm_metric_include = []
host_metric_include = []
cluster_metric_include = []
datastore_metric_exclude = ["*"]
max_query_metrics = 256
timeout = "60s"
insecure_skip_verify = true
## Historical instance
[[inputs.vsphere]]
interval = "300s"
vcenters = [ "https://{{ vcenter }}/sdk" ]
username = "{{ vcenter_username }}"
password = "{{ vcenter_password }}"
datastore_metric_include = [ "disk.capacity.latest", "disk.used.latest", "disk.provisioned.latest"]
insecure_skip_verify = true
force_discover_on_init = true
host_metric_exclude = ["*"] # Exclude realtime metrics
vm_metric_exclude = ["*"] # Exclude realtime metrics
max_query_metrics = 256
collect_concurrency = 3
Comme à mon habitude, j’exploite ansible pour faciliter le déploiement du fichier, d’où les variables {{}} présente dans mon fichier qui doivent être remplacées par leur véritable valeur. La partie en vert concerne l’accès à la base influxdb. Telegraf va ainsi renvoyer les informations qu’il collecte vers cette dernière. Ayant déployé influxdb et telegraf sur le même serveur, j’utilise comme adresse localhost.
Le reste de la configuration concerne l’interrogation du vcenter. J’ai directement repris la configuration proposée par l’auteur des dashboards grafana. Ce dernier a décidé de mettre en œuvre deux collectes, l’une pour des données temps réels l’autre pour des données historisées. Dans les deux cas, il faut indiquer les accès au vCenter. Personnelement, j’ai créé un compte de service en lecture seul pour cet usage.
Attention au paramètre insecure_skip_verify. Il est ici placé à True car j’utilise des certificats autogénérés. Dans une situation de production, il faudra peut être aller plus loin en paramétrant correctement cette partie (configuration disponible dans la doc du plugin).
Intégration dans Grafana
Il reste maintenant à connecter grafana à ma base influxdb. (j’utilise le même login et password que pour telegraf)
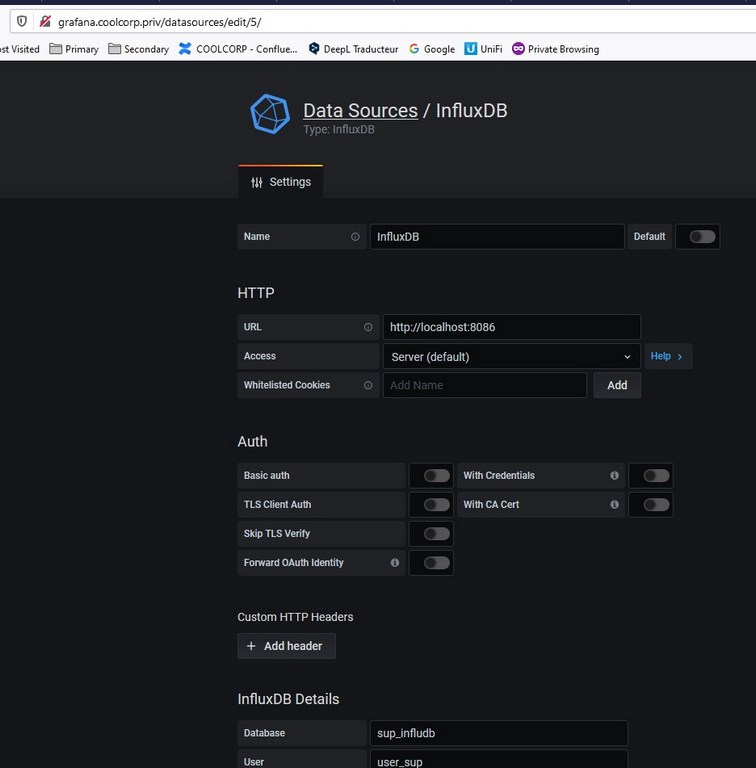
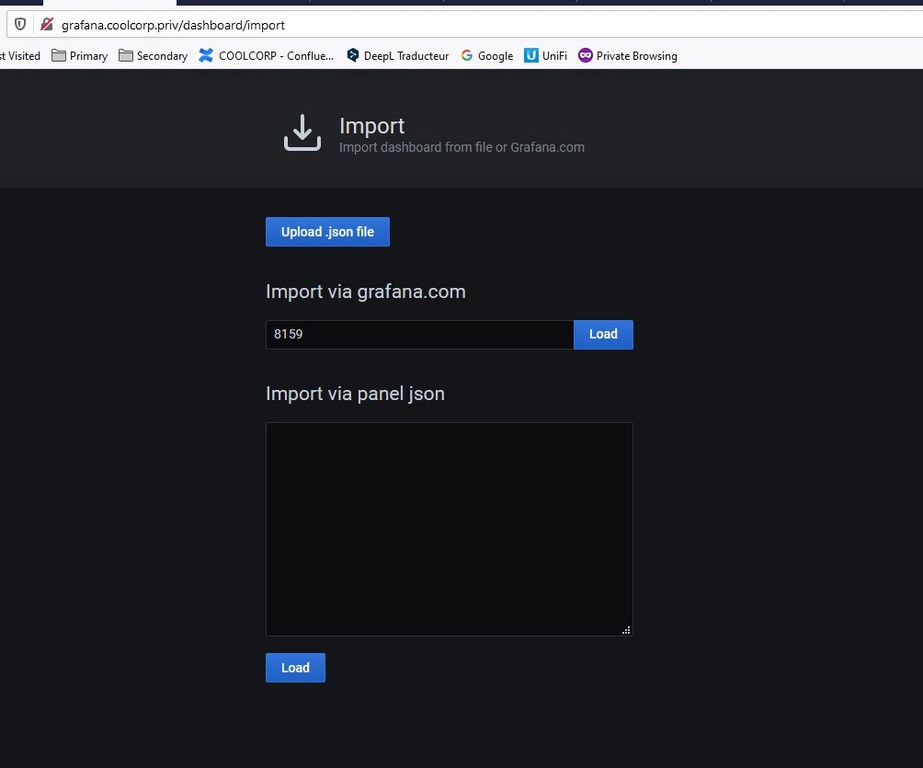
J’ajoute les dashboards trouvés sur le site de grafana.
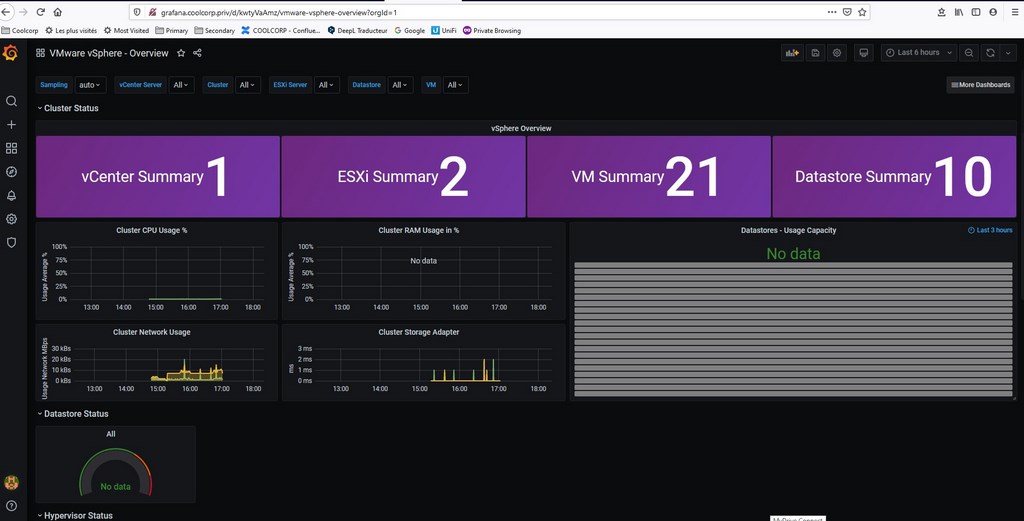
Conclusion
J'ai maintenant accès à des graphiques intéressants sur le fonctionnement de mon petit lab. Il va désormais falloir creuser toutes ces informations et prendre le temps d’identifier ce qui m’est réellement utile. Si c’est sympa d’avoir une œuvre d’art comme console de supervision, ce n’est pas forcément la garantie de correctement surveiller son architecture.
Pour aller plus loin, je considère que des outils comme vROPS restent totalement légitimes et un "must have" sur des infrastructures conséquentes sous ESXi (a priori logique vu qu’il s’agit de vmware dans les deux cas). Cependant la solution est loin d’être bon marché et couvre bien d'autres besoins que la supervision. Mais pour avoir une premiere vision pertinente de son architecture vmware , l’association grafana, infludb et telegraf peut se montrer très interessante surtout si l'on ne dispose pas déja de solutions en place. Dans le cas contraire elle peut ammener à un complément d'information à des outils déja en oeuvre (avec la réserve d'avoir à gérer et à maintenir de nouveaux applicatifs).