Elements de centralisation des logs pour Kubernetes
Introduction sur les logs et leur exploitation
Cet article impose la lecture de mon post précédent sur la supervision au sein de Kubernetes, car il fait référence à des concepts et solutions présentés dans ce dernier.
En plus des traditionnels compteurs et métriques de monitoring, l’exploitation des logs est devenue capitale dans l’univers de la supervision…pardon de l’observabilité.
Solution de gestion des logs
De nombreuses solutions dédiées à ce besoin sont disponibles sur le marché, les plus connus actuellement étant Elasticsearch dans l’univers Open Source et Splunk en produit payant.
Un nouvel acteur, plus récent, est également disponible : Loki.
Open source, proposé par grafana et construit sur le même modèle que prometheus, il gagne progressivement en popularité. Il n’est pas vraiment un concurrent direct aux deux solutions citées précédemment, mais plutôt une alternative. En effet, Loki ne vise pas un besoin avancé d’analyse des logs, mais une centralisation de ces derniers, de façon simple et surtout très performante. Sa grosse différence étant qu’il n’indexe pas tous les champs comme pourrait le faire Elasticsearch ou Splunk. Son principal avantage réside dans son intégration avec l’écosytème grafana/prometheus, qui permet très facilement de construire des dashboards regroupant métriques et logs. Ce qui peut s’avérer très pratique pour faire des corrélations et identifier des incidents.
Configuration de Loki
Cet article n’a pas vocation à détailler l’installation et l’usage de Loki, mais à complèter les éléments décrits dans mon post sur la supervision dans Kubernetes pour ajouter l’exploitation des logs.
Je vais tout de même rapidement décrire ma configuration. Dans mon cas, j’ai choisi de le déployer sur mon serveur (VM Ubuntu 20.04) dédié à la supervision de mon lab personnel. Jy’ai déjà installé Prometheus, grafana (et nginx pour simplifier l’accès aux différentes URLS). Loki s’installe très facilement à partir du binaire téléchargeable sur le site officiel, je vous laisse prendre connaissance de la documentation associée.
Une fois en place, le serveur loki va être accessible sur le port 3100.
À titre d’exemple voici la configuration de mon serveur
auth_enabled: false
server:
http_listen_port: 3100
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
schema_config:
configs:
- from: 2020-06-01
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 168h
storage_config:
boltdb:
directory: /opt/loki/db/index
filesystem:
directory: /opt/loki/db/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
J’ai simplement personnalisé l’emplacement des indexs qui vont servir au stockage des logs. Je dois encore me pencher sur la partie cycle de vie de la donnée et purge des informations.
Il suffit ensuite dans grafana de sélectionner une nouvelle source de donnée « Loki » qui pointe vers le serveur lui-même (puisque dans mon cas prometheus,grafana et loki sont déployés sur la même VM)
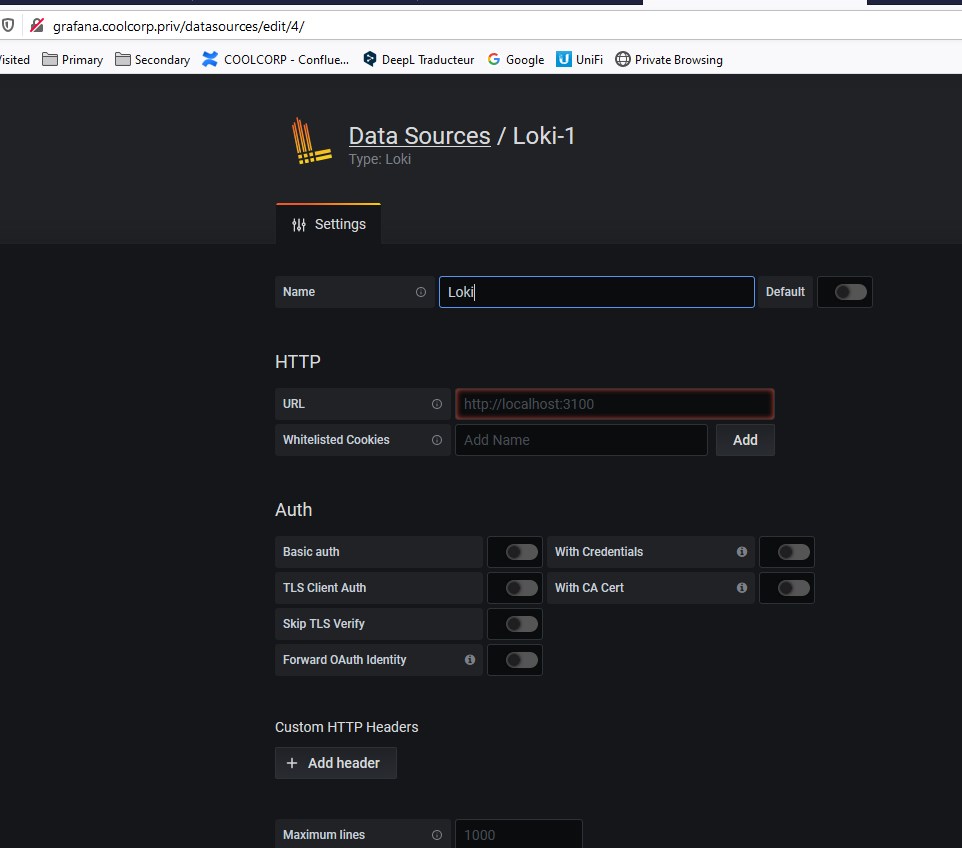
Promtail
Pour alimenter Loki, il faut déployer des « agents » qui se chargent de collecter les logs afin de les mettre à disposition de ce dernier. Plusieurs solutions existent, mais le produit de base associé à Loki est « Promtail ». Comme Prometheus, Promtail fonctionne sur le principe de « découverte » de service. Il peut ainsi découvrir des logs de manière « static » ou dynamic avec Kubernetes.
Personnellement j’ai choisi une logique qui peut largement être critiquée en déployant promtail de deux manières.
- Au niveau OS sur chaque nœud de mon cluster kubernetes : me permet de remonter les logs de l’OS
- Au niveau Kubernetes via un daemonset : me permet de remonter les logs des pods
Je pense qu’il est possible de n’utiliser que le déploiement au sein de Kubernetes, mais comme je l’ai déja expliqué sur mon article concernant la supervision, j’aime avoir des éléments de surveillance externe à ce que je surveille.
Déploiement de promtail sur la couche OS
Je déploie donc promtail en tant qu’agent directement sous Ubuntu en suivant la doc officielle. Petite remarque qui fera sans doute sursauter les adeptes de la sécurité, promtail tourne ici en tant que root, pour être certains d’accéder à tous les logs. Une configuration plus sécurisée devra faire appel à un compte dédié.
Voici le fichier de conf présent sur chaque nœud de mon cluster
# Promtail Server Config
server:
http_listen_port: 9080
grpc_listen_port: 0
# Positions
positions:
filename: /tmp/positions.yaml
# Loki Server URL
clients:
- url: http://{{ loki_server }}:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
host: {{ ansible_fqdn }}
- job_name: systemd-journal
journal:
labels:
job: systemd-journal
host: {{ ansible_fqdn }}
relabel_configs:
- source_labels: ['__journal__systemd_unit']
target_label: 'unit'
pipeline_stages:
- match:
selector: '{job="systemd-journal"}'
stages:
- regex:
expression: ".*(?P<error_message>error*)"
- metrics:
error_total_journal:
type: Counter
description: "total count of errors"
source: error_message
config:
action: inc
Vous remarquerez les variables {{}} propres au déploiement de ce fichier via ansible que j’utilise pour me faciliter la tache. Il ne s’agit que de remplacer dans chaque fichier, l’URL de mon serveur Loki auprès duquel renvoyer les logs et la labélisation avec le nom du host.
La partie en verte traite des logs que l’on peut trouver dans /var/log. Cette partie de la configuration me permet de récupérer tout le contenu des fichiers *.log présent à cet emplacement. J’y applique le label job=varlogs pour les identifier plus facilement dans prometheus.
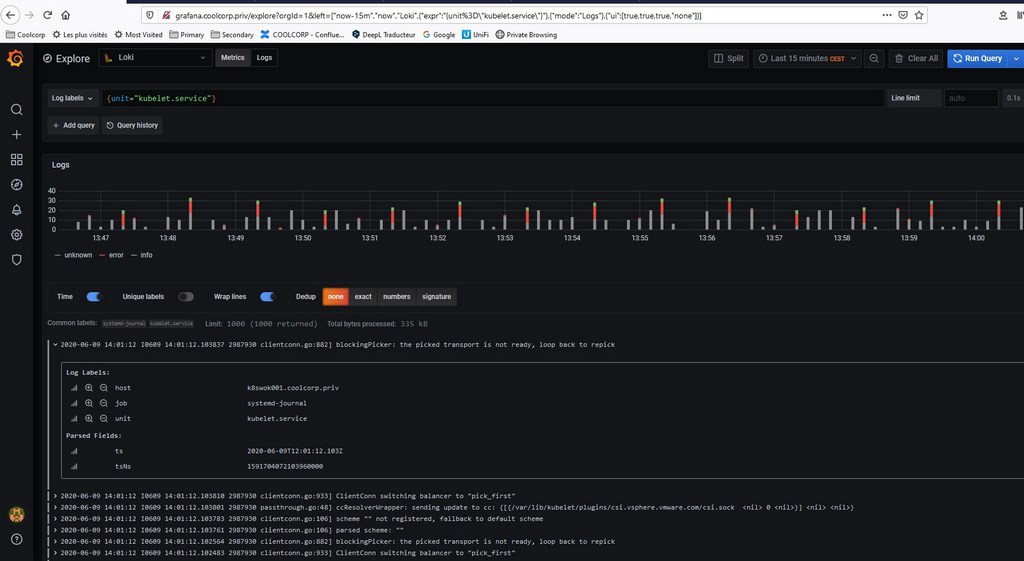
La seconde partie en rouge est la plus intéressante. Grâce au mot clef « journal », je récupère les flux issus de systemd, comme par exemple les logs générés par les agents kubelet. Grâce au tutoriel présenté ici , j’y ai ajouté une pipeline de traitement. Celle-ci me permet de « matcher » le mot clef « error » et d’alimenter un nouveau compteur appelé « error_total_journal ». Ainsi il est possible dans prometheus d’avoir un compteur d’erreurs de logs qui s’incrémente si le mot "erreur" est détecté sur le flux de log.
Via grafana, je peux maintenant identifier les logs liés à un service particulier, comme celui des agents kubelet.
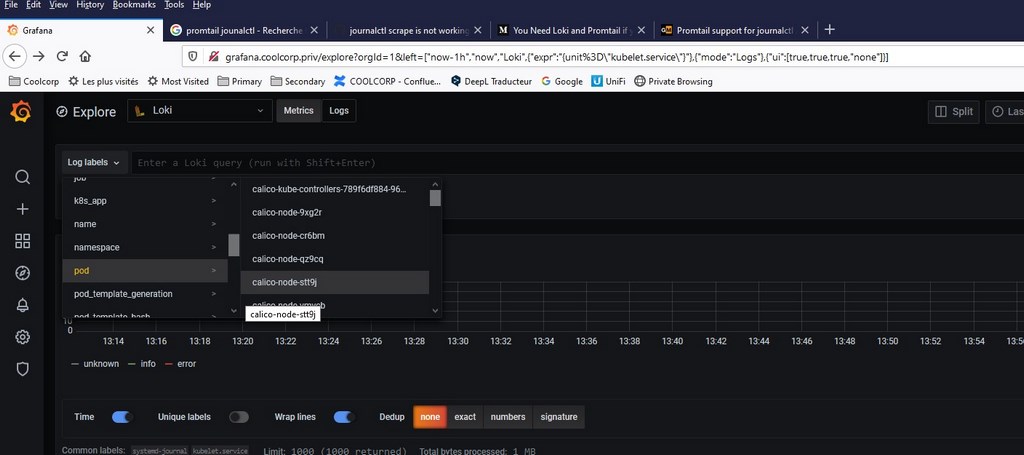
Déploiement de Promtail dans Kubernetes
Pour un déploiement de promtail sur kubernetes, j’utilise « Helm ». Helm est un gestionnaire de package pour kubernetes qui vous permet de déployer très facilement des « charms » soit des applications complètes sur votre cluster Kubernetes. C’est très pratique, et l’on trouve de nombreux modèles de déploiement. Depuis la version 3, son usage est encore simplifié puisque la récupération du binaire est suffisante pour l’utiliser sans avoir la nécessité de déployer un composant sur le cluster K8S (Tiller)
Une fois le binaire pour Windows téléchargé, j’ajoute le repo de loki/promtail
helm repo add loki https://grafana.github.io/loki/charts
helm repo update
J’installe uniquement la partie promtail :
helm upgrade --install promtail loki/promtail --set "loki.serviceName=loki" -n supervision
Je précise l’usage d’un namespace spécifique « supervision » que j’ai créé dans mon article précédent pour éviter de déployer les pods promtail dans le namespace par défaut.
Le déploiement est basé sur un objet daemonset, qui permet d’avoir une instance de promtail par nœud K8S.
C’est tout particulièrement ici que la lecture et la mise en oeuvre des éléments que je décris dans la partie sur la supervision Kubernetes est importante, car c’est un prérequis obligatoire pour permettre le bon fonctionnement de promtail tel que déployé ici.
En effet, prometheus étant déjà paramétré pour interroger l’API de mon cluster et la découverte des métriques, j’obtiens tous en ensemble de nouveaux labels dans grafana, lorsque je sélectionne loki comme source de données
J’ai maintenant accès à un maximum de logs issus de chaque conteneur.
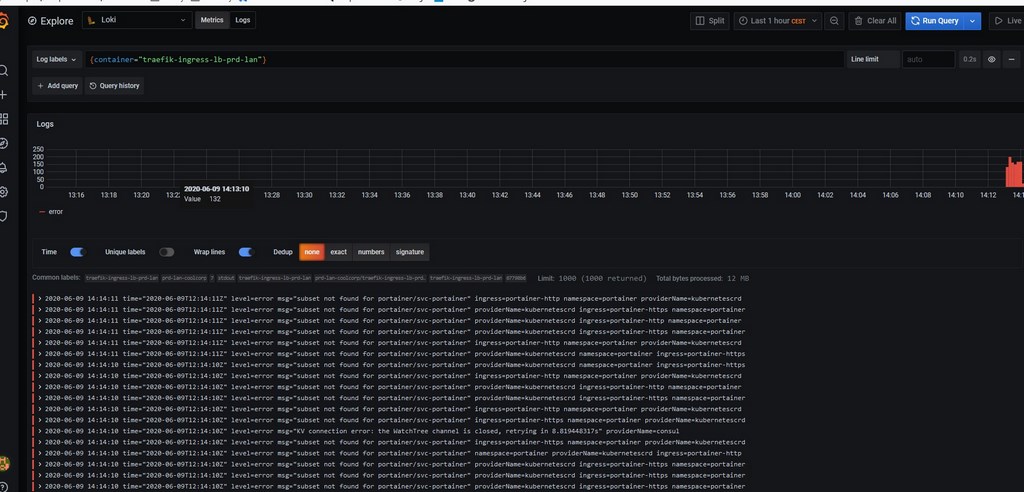
En combinant les métriques de prometheus et les logs de de loki dans grafana, je peux maintenant créer des dashboards regroupant les deux types de données comme par exemple, pour l’application confluence que j’ai déployée dans la dernière partie de mon tutoriel sur Kubernetes.
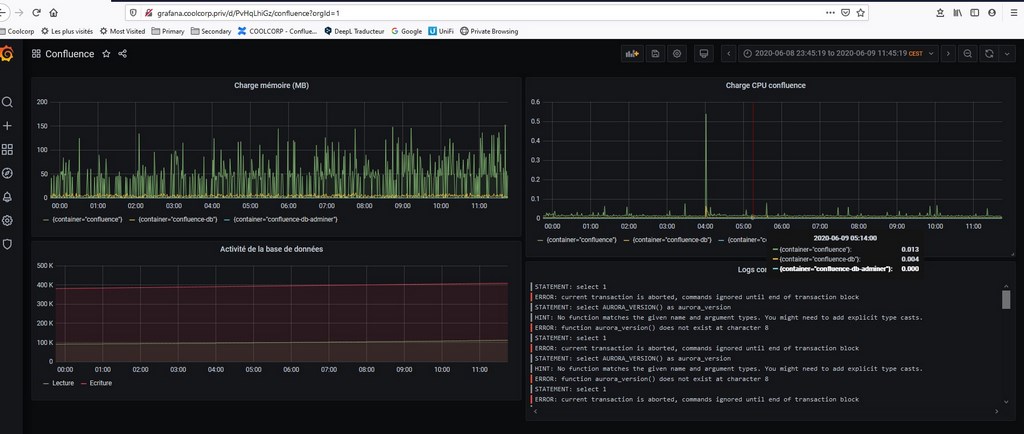
Loki est un outil extrêmement intéressant qui prend tout son sens avec le duo prometheus/grafana. Je n’ai pas l’expérience du produit sur un usage de production, mais il semble séduire de plus en plus de personnes. Son intégration dans Kubernetes est très bien faite et facilite grandement la récolte des logs.
Étant beaucoup plus familier avec un produit comme Splunk, il me parait évident que les capacités d’analyse et d’extraction de l’information de Loki sont bien inférieures, mais ce n’est pas l’objectif premier de Loki. Sa mise en œuvre et ses besoins techniques sont bien moins élevés que Splunk. Je ne connais ElasticSearch que de nom, et s’il a très bonne réputation, j’ai souvent entendu dire que c’est un produit très gourmant en ressource. C’est pourquoi, je pense que Loki a belle avenir devant lui, car il comblera déjà un très grand nombre de besoins sans devoir à investir trop de temps et d’équipements. C’est un outil parfaitement adapté à « l’observabilité » d’un cluster Kubernetes.