Déploiement d'une application sur le cluster Kubernetes
Introduction et choix d'une application
À quoi bon déployer un cluster K8S si ce n’est pas pour y faire tourner des applications.
Cette étape est donc l’aboutissement du lab. J’ai choisi de déployer l’application « confluence ». C’est une solution bien connue pour mettre en œuvre un wiki et un espace de travail communautaire. Elle fait appel à une base de données et à une partie frontend.
Je pense que c’est un bon exemple, car je vais devoir utiliser du stockage persistant, plusieurs services et pods.
Cette fois-ci pas de tutoriel de référence, j’y vais de ma création hormis les instructions des éditeurs pour la mise en place de leur conteneur respectif issu du docker hub.
Déploiement de confluence sous Kubernetes
J’ai organisé mon déploiement en 7 fichiers yaml (hors fichier des storageclass)
|
01-pvc-persistent-volume-storageclass.yml |
Création des objets PersistentVolumeClaim « dynamique » pour l’hébergement de la base de données et des binaires de confluence. Ils sont rattachés à des StorageClass correspondant à mes datastore vmware. Ils vont donc utiliser le fameux drivers CSI vSphere. |
|
02-dep-confluencedb.yaml |
Le fichier de déploiement de la base postgreSQL dédiée à confluence. J’ai décidé en plus du conteneur postgreSQL d’ajouter au pod un conteneur adminer afin d’avoir un accès graphique aux bases. Cela va me permettre d’illustrer le principe de « side car », soit un conteneur secondaire qui fournit un service complémentaire au conteneur principal. |
|
03-svc-confluencedb.yaml |
Le service associé à la base de données et son administration. |
|
04-route-confluencedb.yaml |
L’objet route traefik pour l’accès à la GUI adminer |
|
05-dep-confluence.yaml |
Déploiement de l’application confluence |
|
06-svc-confluence.yaml |
Service associé à confluence |
|
07-route-confluence.yaml |
L’objet route traefik pour l’accès à confluence |
Les StorageClass
La première étape est de s’assurer de la bonne déclaration des storageclass dont je vais avoir besoin pour le stockage des données persistantes.
Une storageclass est transverse à tout le cluster et n’est pas isolée au sein d’un namespace. Pour rappel, j’ai utilisé ce type d'objet en fin d’étape 4 pour valider le bon déploiement de la couche CPI/CSI vSphere.
J’utilise deux classes différentes pour confluence.
- vsphere-storageclass-volume-nfs-readwrite
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: vsphere-dts-nfs
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: csi.vsphere.vmware.com
allowVolumeExpansion: true
reclaimPolicy: Delete
parameters:
#storagepolicyname: "VMW_K8S_NFS"
datastoreurl: ds:///vmfs/volumes/49c9734e-84c4ea9d/
Cette première classe qui utilise un datastore NFS est plutôt orientée pour des besoins d’espace au détriment de la performance : parfait pour le stockage des binaires confluence.
- vsphere-storageclass-volume-ssd-readwrite.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: vsphere-dts-ssd
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.vsphere.vmware.com
allowVolumeExpansion: true
reclaimPolicy: Delete
parameters:
#storagepolicyname: "VMW_K8S_SSD"
datastoreurl: ds:///vmfs/volumes/5e179fa4-b8a6bbc6-80e3-001b219adf10/
Cette seconde classe (qui est annotée comme étant celle par défaut) utilise un datastore SSD pour des besoins plutôt orientés perf au détriment de l’espace disponible : parfait pour le stockage de la base de données.
Après avoir déployé ces objets, on peut vérifier qu’ils sont bien disponibles avec la commande « kubectl.exe get storageclass »

On note la notion de « Reclaim Policy » configurée à « Delete ». Je n’ai pas été vérifier, mais je suppose que cela indique que si un volume configuré pour utiliser cette classe est supprimé du cluster K8S, alors sa data est effectivement supprimée. C’est un point important, on peut paramétrer le comportement différemment. Par exemple, dans l’objectif de conserver la donnée même si les objets Kubernetes rattachés n’existent plus. Dans mon cas, si je supprime les PersistentVolumeClaim, je perds les données.
Déploiement de objets K8S pour la base de données
Je vais maintenant déployer les objets Kubernetes que j’ai présenté en introduction.
Déploiement des objets liés au stockage
Je débute par le fichier 01-pvc-persistent-volume-storageclass.yml pour utiliser nos fameuses classes de storage.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-confluence-apps
namespace: prd-lan-coolcorp
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: vsphere-dts-nfs
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-confluence-db
namespace: prd-lan-coolcorp
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 15Gi
storageClassName: vsphere-dts-ssd
kubectl.exe apply -f .\01-pvc-persistent-volume-storageclass.yml
Arriver à ce stade, je vérifie si tous mes PersistentVolumeClaim ont bien été associés avec la commande :
kubectl.exe get PersistentVolumeClaim --namespace=prd-lan-coolcorp

Création d'un objet secret
Avant d'aller plus loin, je défini un objet "secret" pour contenir le login et le mot de passe d'accès à ma base de données associée à Confluence.
kubectl create secret generic sec-prd-confluencedb --from-literal="password=monpassword" --from-literal="user=monuser" --namespace=prd-lan-coolcorp
Création de l'objet Deployment pour la base de donnée Postgre sous K8S
Les prérequis étant posées, je vais maintenant déployer la base de données via le fichier 02-dep-confluencedb.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dep-confluencedb
namespace: prd-lan-coolcorp
labels:
app: confluence
tiers: database
zone: lan
env: prd
spec:
selector:
matchLabels:
app: confluence
tiers: database
replicas: 1
template:
metadata:
namespace: prd-lan-coolcorp
labels:
app: confluence
tiers: database
zone: lan
env: prd
spec:
containers:
- name: confluence-db
image: postgres:9.6.16-alpine
imagePullPolicy: Always
resources:
limits:
memory: 1000Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
volumeMounts:
- mountPath: "/var/lib/postgresql/data/"
name: data-confluence
env:
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: sec-prd-confluencedb
key: password
- name: POSTGRES_DB
value: confluencedb
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: sec-prd-confluencedb
key: user
- name: PGDATA
value: /var/lib/postgresql/data/db-files/
- name: POSTGRES_INITDB_ARGS
value: "--encoding=UTF8"
ports:
- containerPort: 5432
- name: confluence-db-adminer
image: adminer
imagePullPolicy: Always
resources:
limits:
memory: 500Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
ports:
- containerPort: 8080
volumes:
- name: data-confluence
persistentVolumeClaim:
claimName: pvc-confluence-db
J’utilise un objet de type Deployment avec un réplica de 1 qui va s’assurer qu’à tout instant 1 instance d’un pod impliquant 2 conteneurs est disponible sur le cluster.
Au sein d’un pod, je vais donc avoir un moteur postgreSQL avec lequel il va m’être possible d’interagir via un simple navigateur web grâce à l’application adminer.
Les options à passer à la base sont définies dans le champ env et sont issues des instructions données sur le docker hub pour utiliser un conteneur Postgre. Le mot de passe et l’utilisateur de la base est récupéré de mon objet secret créer précédemment grâce aux instructions valueFrom:secretKeyRef:
J’utilise également la notion de requests pour m’assurer d’avoir un minimum de ressource CPU et mémoire au lancement du conteneur, mais également la notion de limits pour éviter que mon conteneur se mettent à consommer toutes les ressources disponibles sur le node.
kubectl.exe apply -f .\02-dep-confluencedb.yaml
Création d'un objet service pour l'accès à la base de données
La base étant déployée avec ses données stockées sur un volume persistant, il va maintenant falloir la rendre accessible aux autres pod via un service.
C’est ce que je fais avec le ficheri yaml 03-svc-confluencedb.yaml
apiVersion: v1
kind: Service
metadata:
namespace: prd-lan-coolcorp
name: svc-confluencedb
labels:
app: confluence
zone: lan
env: prd
tiers: database
spec:
#clusterIP: None
ports:
- name: postgre
port: 5432
targetPort: 5432
- name: adminer
port: 8080
targetPort: 8080
selector:
app: confluence
tiers: database
Le service me permet à la fois d’exposer le port 5432 pour postgreSQL mais également le port 8080 rattaché à adminer.
kubectl.exe apply -f 03-svc-confluencedb.yaml
Publication externe de l'outil adminer
Si l’instance postgreSQL n’a pas besoin d’être accédée à l’extérieur du cluster K8S, c’est le cas de adminer. J' utilise donc un objet IngressRoute pour que Traefik puisse fournir un accès externe.
C’est le rôle du fichier 04-route-confluencedb.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: confluencedb-admingui-http
namespace: prd-lan-coolcorp
spec:
entryPoints:
- web
routes:
- kind: Rule
match: Host(`confluencedb.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-confluencedb
port: 8080
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: confluencedb-admingui-https
namespace: prd-lan-coolcorp
spec:
entryPoints:
- websecure
routes:
- kind: Rule
match: Host(`confluencedb.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-confluencedb
port: 8080
tls:
certResolver: le
kubectl.exe apply -f 04-route-confluencedb.yaml
J’ai maintenant un accès HTTP et HTTPS à l’outil via l’URL confluencedb.inf.prd.k8s.coolcorp.priv
Bien entendu, il faut que cette URL pointe vers l’entrée DNS de mon loadbalancer HAProxy comme vu dans la partie 6 ou j’ai déployé Traefik.
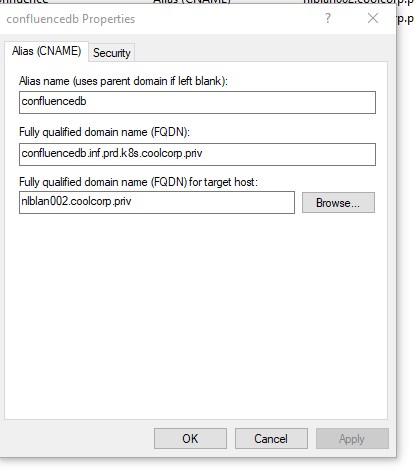
Je teste maintenant l’accès à adminer via mon navigateur
Adminer est intégré au pod qui contient l’instance PostgreSQL. Tous les conteneurs qui sont au sein d’un même pod se partagent la même configuration réseau, donc la même IP ( à noter qu’il est donc impossible d’avoir au sein d’un pod des conteneurs qui partagent le même port).
Cela simplifie les choses puisque je vais pouvoir utiliser l’IP de localhost 127.0.0.1 pour la connexion.
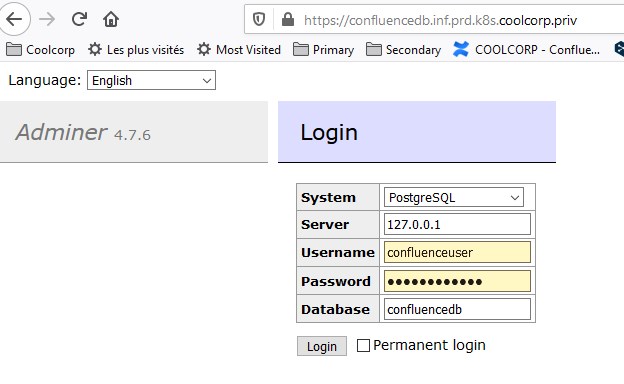
J’accède bien à ma base.
Déploiement des objets Kubernetes pour Confluence
Création de l'objet Deployment pour Confluence sous Kubernetes
La base étant prête, j'utilise maintenant mon fichier 05-dep-confluence.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: dep-confluencenamespace: prd-lan-coolcorplabels:app: confluencetiers: appzone: lanenv: prdspec:selector:matchLabels:app: confluencetiers: appreplicas: 1template:metadata:namespace: prd-lan-coolcorplabels:app: confluencetiers: appzone: lanenv: prdspec:containers:- name: confluenceimage: atlassian/confluence-server:7.4imagePullPolicy: Alwaysresources:limits:memory: 2500Micpu: 2requests:memory: 500Micpu: 500mvolumeMounts:- mountPath: "/var/atlassian/application-data/confluence/backups"name: backup-confluence- mountPath: "/var/atlassian/application-data/confluence"name: apps-confluenceenv:- name: ATL_PROXY_NAMEvalue: confluence.coolcorp.priv- name: ATL_JDBC_URLvalue: jdbc:postgresql://svc-confluencedb:5432/confluencedb- name: ATL_JDBC_USERvalueFrom:secretKeyRef:name: sec-prd-confluencedbkey: user- name: ATL_JDBC_PASSWORDvalueFrom:secretKeyRef:name: sec-prd-confluencedbkey: password- name: ATL_DB_TYPEvalue: postgresql- name: JVM_MINIMUM_MEMORYvalue: 1024m- name: JVM_MAXIMUM_MEMORYvalue: 1024m- name: ATL_TOMCAT_SECUREvalue: "true"- name: ATL_TOMCAT_SCHEMEvalue: httpsports:- containerPort: 8090volumes:- name: backup-confluencenfs:path: /volume1/k8s-psv-nfs-rwm/confluence-lan-prd/backupserver: storage.coolcorp.privreadOnly: false- name: apps-confluencepersistentVolumeClaim:claimName: pvc-confluence-apps
kubectl.exe apply -f .\05-dep-confluence.yaml
Encore une fois, j’utilise les instructions données sur le docker hub de l’image confluence-server proposée par l’éditeur pour configurer les éléments dans la rubrique env. Je fais à nouveau appel à mon secret pour récupérer l’utilisateur et le mot de passe d'accès à la base de données.
Le point important concerne les paramètres limits. Confluence utilise Java et consomme une quantité de mémoire importante. J’ai été confronté durant mes tests à l’efficacité de K8S quand à son devoir de faire respecter les limites de consommations qu’on lui demande. J’avais utilisé une valeur trop faible pour la mémoire. A un moment donné le conteneur Confluence s’est mis à dépasser ce seuil. La sanction a été immédiate : redémarrage du conteneur. J’ai cru comprendre que c’est une bonne pratique de toujours indiquer des limites et des réservations dans ses pods, mais il faut à ce moment être attentif aux valeurs qu’on positionne.
Concernant le stockage, j'utilise à la fois une référence à un objet PersistentVolumeClaim (apps-confluence) et un accès direct NFS (backup-confluence). Ce dernier étant juste un partage NFS pour héberger les backups de confluence réalisés sous format d'archive.
Autre remarque, lorsqu’on évoque Kubernetes, on pense la plupart du temps au microservice. Dans cet univers le démarrage d’un conteneur est quasi instantané et opérationnel dès son lancement, car optimisé pour réaliser une tache unitaire et spécialisée. Dans mon exemple, Confluence est loin d’être un microservice. Son image contient de nombreux composants dont l’initialisation peut prendre du temps. Il faut se montrer patient et si ma commande kubectl.exe get pod --namespace=prd-lan-coolcorp -o wide me confirme que mon pod est lancé, cela ne veut pas forcément dire que confluence est prêt.

De toute façon pour l’instant, Confluence n’est accessible à personne puisque associé a aucun service.
Création d'un service pour l'accès à confluence au sein du cluster K8S
Je rémedie à cela avec mon fichier 06-svc-confluence.yaml
apiVersion: v1
kind: Service
metadata:
namespace: prd-lan-coolcorp
name: svc-confluence
labels:
app: confluence
zone: lan
env: prd
tiers: app
spec:
#clusterIP: None
ports:
- name: apache
port: 8090
targetPort: 8090
selector:
app: confluence
tiers: app
kubectl.exe apply -f .\06-svc-confluence.yaml
Confluence est maintenant accessible au sein du cluster sur le port 8090 mais pas directement depuis mon poste de travail.
Publication externe de confluence
Je crée un objet IngressRoute dans mon fichier 07-route-confluence.yaml.
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: confluence-http
namespace: prd-lan-coolcorp
spec:
entryPoints:
- web
routes:
- kind: Rule
match: Host(`confluence.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-confluence
port: 8090
middlewares:
- name: https-redirectscheme
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: confluence-https
namespace: prd-lan-coolcorp
spec:
entryPoints:
- websecure
routes:
- kind: Rule
match: Host(`confluence.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-confluence
port: 8090
tls:
certResolver: le
kubectl.exe apply -f .\07-route-confluence.yaml
J’ai désormais grâce à traefik un accès HTTP et HTTPS à confluence via l’URL confluence.inf.prd.k8s.coolcorp.priv. J'ai également la référence à mon objet middleware https-redirectscheme créé dans la partie précedente pour avoir une redirection automatique de http vers https.
Bien entendu, il me faut ma redirection DNS vers mon loadbalancer HAproxy
Une fois toutes les opérations effectuées, j' accède à confluence .
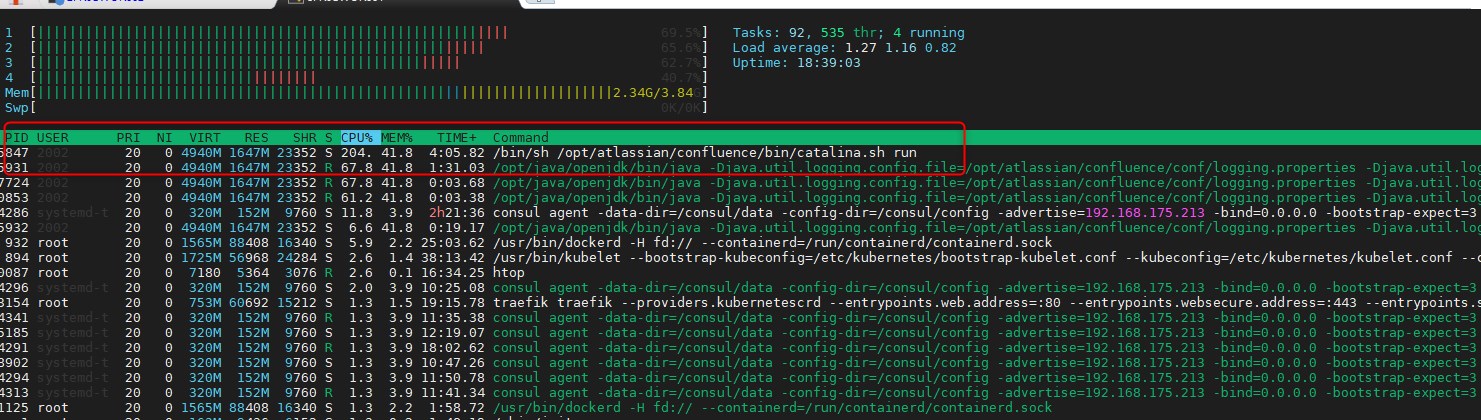
À noter que lorsque je m'assure du lancement du pod, je vois que celui-ci est exécuté sur mon node K8SWOK001
C’est facilement vérifiable en observant la charge sur ce nœud. On voit bien que le processus associé à Confluence est bien chargé et surtout qu’il consomme une quantité de mémoire non négligeable, d’où l’importance des options limits dans le fichier de déploiement associé.
Changement de certificat via Consul
Pour l’instant le certificat utilisé pour sécuriser la connexion en HTTPS est celui que j’ai positionné par défaut et qui correspond à des domaines en *.inf.prd.k8s.coolcorp.priv.
Je souhaiterais maintenant plutôt avoir une URL pour confluence en confluence.coolcorp.priv. Je vais donc générer une clef et un certificat associé à cette URL avec ma propre PKI. (une PKI Microsoft sur un domaine AD)
Pour demander à Traefik d’utiliser ce nouveau certificat, j'utilise Consul que j'ai déployé en étape 5.
Je me connecte donc à l’URL de consul https://consul-traefik-lan.inf.prd.k8s.coolcorp.priv .
Dans l’arborescence traefik, je crée une sous branche tls, qui contient elle-même une sous branche certificates
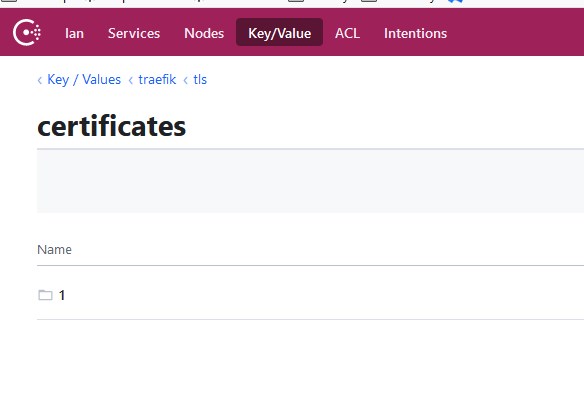
Je crée encore une sous-branche appelée 1
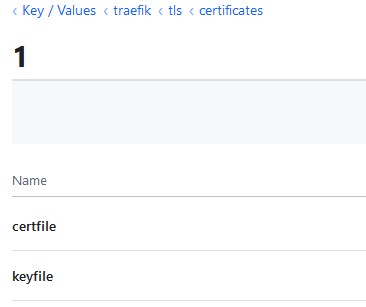
Cette sous-arborescence héberge deux clefs, l’une appelé cerfile et l’autre keyfile
Ces clefs contiennent respectivement l’emplacement de la clef et du certificat que j’ai généré avec ma PKI
Ces emplacements sont les chemins vus depuis les conteneurs traefik grace aux volumes configurés dans l’étape 6 et associés aux pods traefik
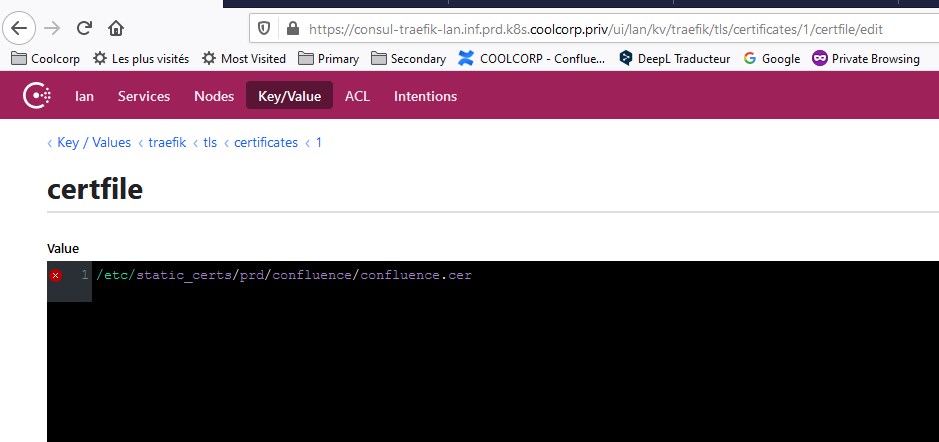
L’un des ces volumes pointe en faite vers un partage NFS. C’est dans ce partage que je copie la clef et le certificat.
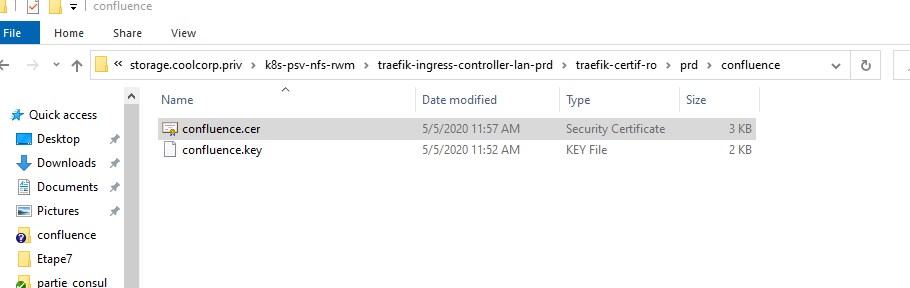
C’est ainsi que chacun des mes conteneurs traefik lancés au sein de mes pods peuvent accéder aux fichiers via le chemin d’accès que j’ai positionné dans Consul.
Il ne me reste qu'à mettre à jour le fichier 09-route-confluence.yaml pour modifier la règle de routage Traefik avec la nouvelle URL
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata:name: confluence-httpnamespace: prd-lan-coolcorpspec:entryPoints:- webroutes:- kind: Rulematch: Host(`confluence.coolcorp.priv`)services:- name: svc-confluenceport: 8090middlewares:- name: https-redirectscheme---apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata:name: confluence-httpsnamespace: prd-lan-coolcorpspec:entryPoints:- websecureroutes:- kind: Rulematch: Host(`confluence.coolcorp.priv`)services:- name: svc-confluenceport: 8090tls:certResolver: le
kubectl.exe apply -f .\09-route-confluence.yaml
Bien entendu, il ne faut pas oublier de créer l’alias DNS correspondant et qui renvoie toujours vers mon Load Balancer HAProxy
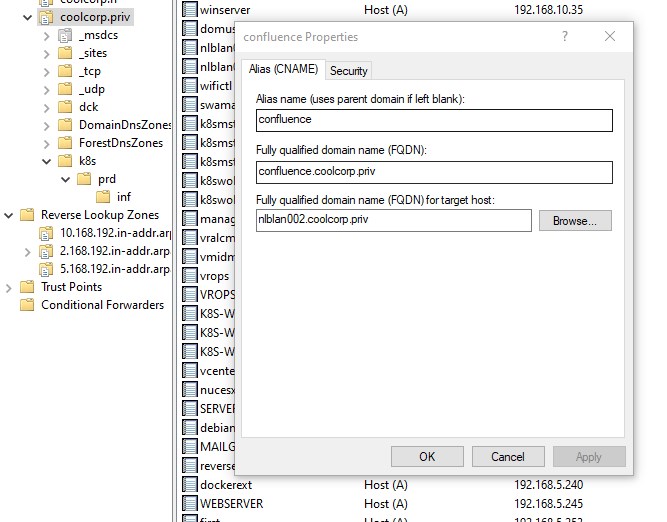
Je vérifie
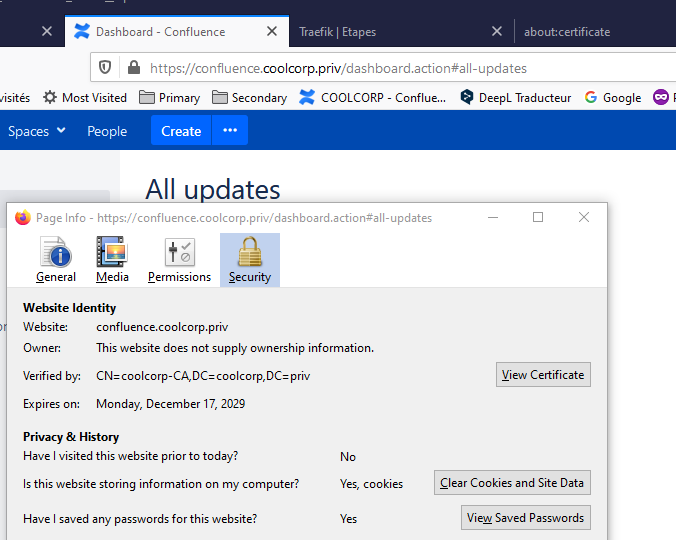
J’ai mon nouveau certificat associé à mon URL. Traefik va automatiquement sélectionner le certificat qui correspond à l’adresse que j’essaye d’atteindre, et s’il n’en trouve pas il utilise celui par défaut. Pour ajouter de nouveaux certificats il me suffira de créer une nouvelle entrée dans Consul et d’indiquer les emplacements des fichiers en les ayant au préalable copiés dans le partage NFS.
Conclusion
Le déploiement de Confluence via Kubernetes a permis de réutiliser beaucoup d’éléments configurés dans les étapes précédentes
- volumes déclarés de façon statique sur des partages NFS
- volumes déclarés de façon dynamique exploitant le provider vSphere
- usage de Traefik pour router et accéder aux applications
- usage de Consul pour configurer Traefik
C’est un mélange de ce qui a été présenté précédemment et démontre qu’une application plutôt « traditionnelle » peut s’exécuter sur un cluster Kubernetes.
Permettez-moi maintenant de donner mon avis sur le sujet. Certains diront, mais quel est l’intérêt d’utiliser K8S pour cela et ne pas déployer Confluence directement sur une bonne vieille VM. Je leur répondrais « C’est pas faux !». En effet, moi qui est installé l’application selon ces deux modèles, je peux vous certifier qu’un déploiement traditionnel est plus simple et nécessite des prérequis plus basiques. Maintenant tout dépend de votre situation et de vos besoins. Si il est vrai que Kubernetes est plutot associé aux applications dites « cloud native » ou le micro service règne en maitre, le faite de l’utiliser pour un outil comme Confluence peux présenter certains intérêts.
- La portabilité et l’assurance d’avoir des environnements iso. Ce point est surtout l’avantage de passer par des conteneurs.
- Un déplacement facilité d’un hébergement à un autre. On trouve énormément d’offres autour de Kubernetes, on peut alors très bien imaginer basculer Confluence d’un environnement Onprem à un environnement Cloud plus facilement si l’on part à l'origine d’un déploiement sous Kubernetes.
- Une industrialisation/automatisation d’instance Confluence. Une fois la procédure maitrisée et les fichiers yaml versionnés, on peut plus facilement industrialiser le déploiement de confluence, même si je vous l’accorde on peut aussi le faire via des méthodes d’installation plus classique.
- L’usage des outils tiers de l’écosystème Kubernetes. K8S est leader incontesté sur son marché ce qui lui permet d’avoir énormément d’add-on pour lui ajouter des fonctionnalités. Si jusqu’à présent j’ai parlé de Traefik comme solution de reverse proxy, il a également des options de tracing, à l’image d’autre produit comme « Istio ». Cela va permettre d’avoir une supervision avancée de ses images et d’incorporer des notions d’observabilité à ses applications.
On en revient donc à l’éternel débat autour de la hype que peut avoir certains produits dans l’IT. Alors oui, ça fait "bien" d’avoir du Kubernetes dans son parc, mais est-ce vraiment utile ? C’est à chacun de se faire son idée. Dans tous les cas, au même titre que la virtualisation a su s’imposer sur le marché (qui n’a pas au moins une VM dans son parc (par forcement sur vmware…mais avouez qu’on les rencontre souvent), Kubernetes est devenu un standard à part entière qui ne cesse d’évoluer…et ce n’est pas anodin si VMWARE lui-même l’a intégré dans sa version 7 de sa suite vSphere et si tous les plus gros provider cloud public disposent d'une offre Kubernetes managée.
Je terminerais qu’une fois de plus, dans un contexte de vraie production, il resterait encor beaucoup de choses à faire :
- Tester la redondance des éléments
- Mettre en place une méthodologie de sauvegarde et la valider via un test de restauration pour chaque brique de l’architecture (un point très souvent négligé)
- Mettre en place la supervision nécessaire
- Faire des tests de montée en charge
- Faire des tests de sécurité
- Et même si ce n’est plus à la mode, un minimum de documentation
J’essayerais de traiter certains de ces points notamment l’aspect backup/sauvegarde dans des articles dédiés, car à l’heure de l’écriture de cette étape, je n’ai pas les connaissances nécessaires pour m’exprimer sur le sujet.
update : 26/05/2020 : un article est disponible sur la sauvegarde sous Kubernetes