Déploiement du cluster Kubernetes sous vSphere
Nous arrivons maintenant à une étape importante et conséquente : la création du cluster Kubernetes.
Encore une fois je vais m’inspirer du tutorial trouvable ici mais je vais m’en éloigner quelque peu.
Intégration de K8S dans vSphere
Je vais essayer de déployer Kubernetes en préparant l'intégration de la notion de « CNS » soit « Cloud Native Storage » que je configurerais à l'étape suivante. Il s’agit de permettre une communication entre vSphere et Kubernetes pour avoir un provisionnement automatique du stockage. Le tutorial semble utiliser VCP soit « vSphere Storage for Kubernetes », une autre solution toujours utilisée, mais dont il est maintenant conseillé de se détacher pour exploiter « CNS ». Si le sujet vous intéresse, je vous conseille la lecture de cet l’article.
Je vais donc également m’inspirer du tutorial suivant mais en essayant d’utiliser une version plus récente de Kubernetes
Préparation de l’infrastructure vSphere.
Création du compte de service
Afin de permettre à Kubernetes d’interagir avec vSphere il est nécessaire de créer un compte de service que l’on va déclarer dans l’interface d’un ou des vCenter. De mon côté j’ai choisi la facilité en lui attribuant les droits admin sur toute mon infrastructure de POC.

Configuration HAProxy
HAproxy s'installe très facilement via le packet fourni dans le repo d'Ubuntu.
Il va juste être nécessaire de positionner la bonne configuration HAproxy. Pour cela il faut éditer le fichier de configuration /etc/haproxy/haproxy.cfg et ajouter les éléments de configuration suivant:
frontend kub_master
bind *:6443
option tcplog
mode tcp
default_backend kube_master
backend kube_master
mode tcp
balance roundrobin
option tcp-check
server k8smst001 192.168.10.70:6443 check
server k8smst002 192.168.10.71:6443 check
server k8smst003 192.168.10.72:6443 check
Les serveurs de backend à renseigner sont les trois master.
Installation des binaires kubernetes
Il va maintenant falloir installer tous les binaires nécessaires au déploiement de Kubernetes sur les serveurs. Il existe plusieurs manières pour installer les différents rôles et services nécessaires à Kubernetes. De mon côté, et comme on le rencontre souvent, j’ai choisi d’utiliser "kubeadm". L’outil va gérer automatiquement la création du cluster à partir d’un fichier de configuration que l’on va lui soumettre.
Commençons d’abord par ajouter les repos Kubernetes sur les VMs Ubuntu pour ensuite pouvoir installer les binaires. Les commandes suivantes sont à réaliser sur tout les noeuds Kubernetes
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
La dernière commande va permettre de protéger les paquets d’une mise à jour future, un update Kubernetes devant toujours se gérer de façon méticuleuse et pas uniquement avec une simple mise à jour des binaires
sudo apt-mark hold kubelet kubeadm kubectl
Configuration de docker
Je vais utiliser comme moteur de conteneur, Docker. Il va donc falloir commencer par l’installer sur tout les noeuds Kubernetes avec la commande suivante
sudo apt-mark docker.io
Il est nécessaire de configurer le daemon docker pourqu’il utilise comme driver de gestion des cgroup "systemd".
On créer un fichier "daemon.json" avec le contenu suivant
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
On copie ce fichier dans /etc/docker (il est possible que vous ayez à créer ce répertoire) puis on redémarre docker.
sudo systemctl restart docker
Fichier de configuration pour Kubernetes
Je vais maintenant créer le fichier de configuration "kubeadm.conf" que je vais soumettre à kubeadm. Je créer ce dernier dans /etc/kubernetes (il est possible que vous ayez à créer ce répertoire)
Son contenu va être le suivant
---
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: y7yaev.9dvwxx6ny4ef8vlq
ttl: 0s
usages:
- signing
- authentication
kind: InitConfiguration
nodeRegistration:
criSocket: /var/run/dockershim.sock
kubeletExtraArgs:
cloud-provider: external
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 192.168.10.45
- kube.coolcorp.priv
extraArgs:
cloud-provider: external
endpoint-reconciler-type: lease
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: kube.coolcorp.priv:6443
controllerManager:
extraArgs:
cloud-provider: external
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: 1.18.2
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
Les éléments en rouge sont importants :
- 192.168.10.45 : c’est l’IP de ma VIP gérer par mon loadbalancer HAproxy
- kube.coolcorp.priv : C’est le nom DNS associé à ma VIP qui va pointer vers mon serveur HAProxy

-1.18.2: c’est la version de Kubernetes que je vais déployer
Création du cluster
Initialisation du premier noeud master
Je vais maintenant pouvoir créer mon cluster depuis une session root sur mon premier noeud master.
Je lance la commande suivante
kubeadm init --config /etc/kubernetes/kubeadm.conf --upload-certs --v=5
(n’oubliez pas –v=5, c’est très pratique en cas d’échec afin d’avoir les détails de l’erreur)
Au bout de quelques minutes, le premier nœud est initialisé et j’obtiens en sortie les commandes nécessaires à passer sur les autres nœuds pour les ajouter au cluster.
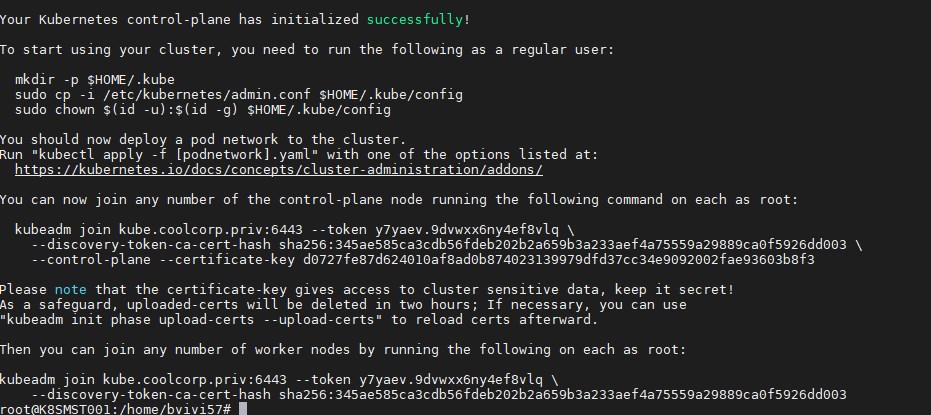
Ajout des noeuds supplémentaires
Pour un node master K8S
kubeadm join kube.coolcorp.priv:6443 --token y7yaev.9dvwxx6ny4ef8vlq \
--discovery-token-ca-cert-hash sha256:345ae585ca3cdb56fdeb202b2a659b3a233aef4a75559a29889ca0f5926dd003 \
--control-plane --certificate-key d0727fe87d624010af8ad0b874023139979dfd37cc34e9092002fae93603b8f3
Pour un node worker K8S
kubeadm join kube.coolcorp.priv:6443 --token y7yaev.9dvwxx6ny4ef8vlq \
--discovery-token-ca-cert-hash sha256:345ae585ca3cdb56fdeb202b2a659b3a233aef4a75559a29889ca0f5926dd003
Récupération de la configuration pour l'accès au cluster K8S
J’obtiens également les commandes nécessaires à la récupération de la configuration de "kubctl" qui va me permettre de piloter mon cluster.
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
À noter qu’il vous suffira de récupérer le binaire windows "kubectl" et de copier le dossier .kube du noeud K8S dans votre profil utilisateur pour pouvoir piloter votre cluster depuis un poste externe sous Windows.
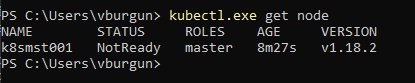
Vérification de l'état des noeuds Kubernetes
On peut d’ailleurs vérifier le statut du cluster avec la commande kubectl get node
Le noeud est “NotReady”, c’est normal pour l’instant.
Je vais maintenant ajouter mes autres noeuds en reprenant les commandes précédents générées à la fin de l’initialisation du cluster en prennant bien soin de ne pas me tromper entre les noeuds master et worker.
À noter qu’il est préférable de procéder noeud par noeud et de ne pas lancer tout en parallèle. Autres remarques, les commandes sont valables sur un laps de temps limité (24H je crois) si les autres noeuds ne sont pas ajoutés sur cette période, le token expire, mais il sera possible d’en regénérer un nouveau si nécessaire (pour ajouter un noeud additionnel plus tard par exemple)
Attention, les commandes sont a passer dans un context root
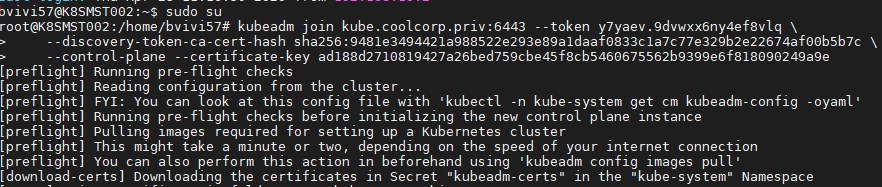
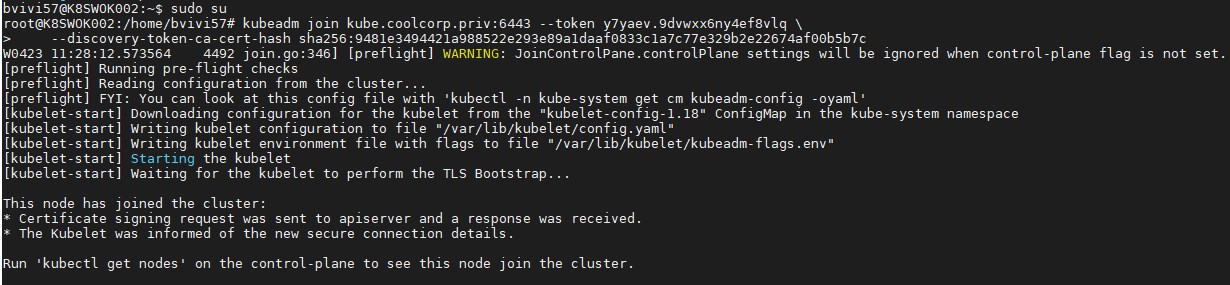
Une fois terminé, si je vérifie l’état de mes noeuds j’arrive au résultat suivant

Tous les noeuds sont dans un état “NotReady”. Ce qui est normal, car je n’ai pas encore déployé un add-on network. En effet pour que la resolution DNS interne au cluster fonctionne et que les pods puissent dialoger sur l’ensemble du cluster il est nécessaire d’implémenter une couche réseau. Il en existe plusieurs qui présentent des caractéristiques différentes et des fonctionnalités spécifiques. C’est à chacun de choisir ce qui lui semble le plus adapté à ses besoins. Pour en savoir plus je vous invite à lire l’excellent article suivant qui détaille les principaux add-on possibles
Par contre attention, le choix de l’add-on peut avoir des conséquences sur le déploiement du cluster, notamment sur l’option “podSubnet:” du fichier de configuration utilisé par kubeadm. De même il peut y’avoir certains prérequis propres à chaque solution. C’est donc un choix à faire en amont du déploiement du cluster.
Installation de l'addon réseau pour K8S
Dans mon cas, j’avais au départ décider d’utiliser "flannel" car il est très utilisé et couvre parfaitement mes besoins. Mais celui-ci vient très récemment (au moment de la rédaction de l’article) d’être "deprecated"
Déploiement de calico
Je vais donc me rabattre sur calico. Le déploiement se fait simplement avec la commande
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
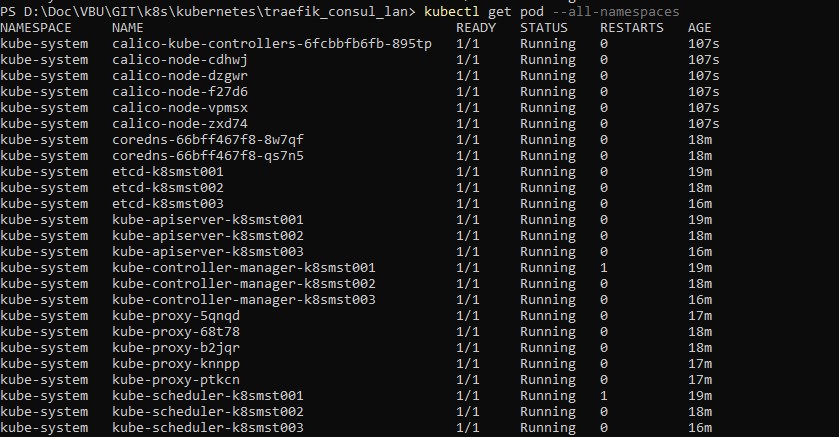
Si je refais un relevé de l’état de mes nodes ils sont maintenant tous à "Ready"

Je vérifie également que tous les pods dans le namespace "kube-system" sont bien démarrés, en particulier les pod "coredns" avec la commande kubectl get pod --all-namespaces
Taches complémentaires
Label des nodes
La notion de label est très importante dans Kubernetes. Par défaut les noeuds master ont bien un label master mais les worker ne sont associé à aucun label pour leur role.
On va donc les marquer comme "worker". On va utiliser les commandes suivantes
kubectl label nodes k8swok001 node-role.kubernetes.io/worker=
kubectl label nodes k8swok002 node-role.kubernetes.io/worker=
Ainsi on a un cluster avec le rôle des nodes bien identifié (utiliser la commande kubectl get node )

Mise en place du dashboard
La dernière partie de cette étape va être de mettre en oeuvre les dashboards optionnels qui permettent d’avoir une vision un peu plus graphique et sympathique de son cluster.
Je vais m’inspirer du tutorial suivant
Création du namespace
Je créer un namespace spécifique qui va service à gérer tous les objets liés aux dashboards
kubectl create namespace kubernetes-dashboard
Création de l'objet service account
Je créer ensuite un objet de type "ServiceAccount" que je décris dans le fichier yaml dashboard-user.yaml dont le contenu est le suivant:
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-user
namespace: kubernetes-dashboard
Puis je l’applique avec la commande kubectl create -f dashboard-user.yaml
Association du compte à un role
Je crée un objet de type "ClusterRoleBinding" dans un fichier rolebinding-dashboard-user.yaml qui va associé le rôle "cluster-admin" à mon compte de service ( à noter qu’en production, il serait sans doute plus opportun de créer un rôle spécifique pour limiter les droits du compte de service)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-user
namespace: kubernetes-dashboard
Je l’applique avec la commande kubectl.exe create -f "rolebinding-dashboard-user.yaml"
Déploiement du dashboard K8S
Enfin j’applique le fichier de déploiement de référence pour la récupération des dashboards (il est possible que ce dernier couvre la création des objets précédents)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended.yaml
Je vérifie le bon déploiement de l’ensemble avec la commande
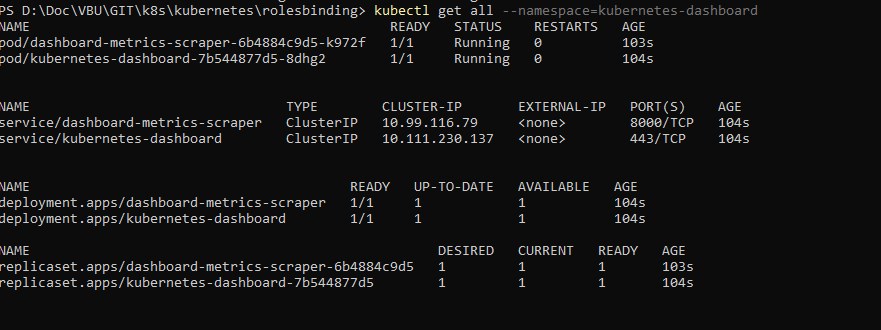
kubectl get all --namespace=kubernetes-dashboard
j’obtiens la liste de tous les objets associés aux dashboard
Accès au dashboard K8S
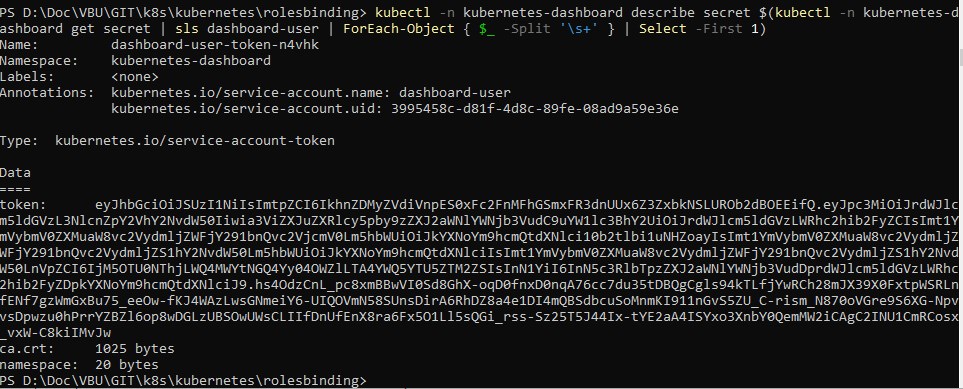
L’authentification pour l’accès au dashboard se fait par un token associé au compte de service.
Je peux me servir de la commande powershell suivante depuis mon poste de travail pour récupérer le token
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | sls dashboard-user | ForEach-Object { $_ -Split '\s+' } | Select -First 1)
Les dashboards ne sont pas accessibles par défaut en dehors du cluster. Je dois donc utiliser la commenda kubectl proxy qui va me permettre, depuis mon poste de travail, d’encapsuler ma requête sur l’ip local de ce dernier vers le cluster. L’accès ne sera donc que possible que depuis mon poste et uniquement le temps que la commande kubectl proxy reste active.
Je peux ensuite accéder au dasboard via l’url http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
J’utilise le token récupéré précédemment
Je peux enfin exploiter les dashboards pour connaitre l’état de mon cluster
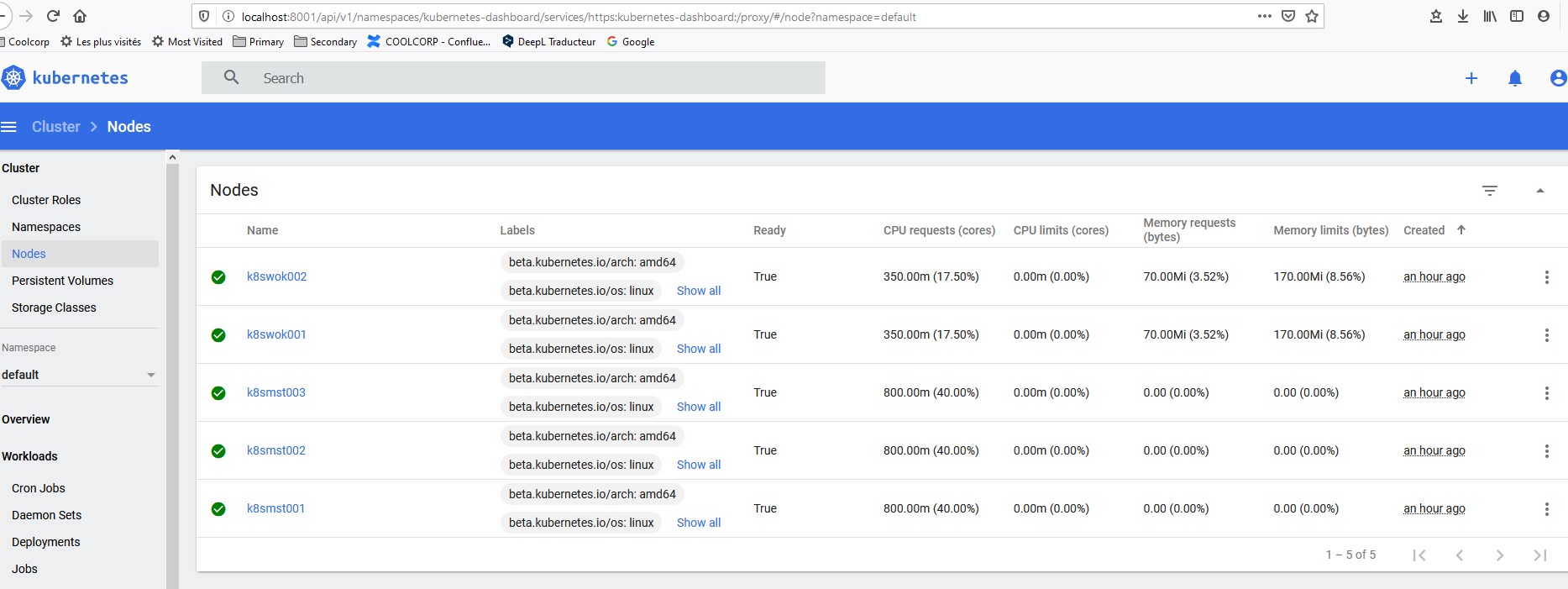
Cela me permet de m’assurer que mon cluster est opérationnel et prêt pour la suite.
Remarques sur le déploiement du cluster K8S
Lorsque j’ai débuté mes essais de déploiement il y’a quelques semaines, j’essayais de déployer mon cluster avec l’add-on network "calico". Je rencontrais des échecs de configuration apparemment liée à l’usage d’Ubuntu 19.10, trop récent pour l’add-on. Je m’étais donc rabattu sur "Flannel" qui fonctionnait très bien. Puis j’ai débuté la rédaction de ce site, en essayant de reproduire ce que j’avais pu tester. Mais entre temps comme rappelé plus haut, "flannel" a été retiré du doc officiel de déploiement d’un cluster Kubernetes avec Kubeadm, m’obligeant à revenir sur "calico".
J’ai à nouveau rencontré un problème sur la montée des pod DNS avec calico. J’ai donc pris la liberté de ne pas utiliser la commande de déploiement issue de la doc official kubernetes qui renvoie vers la version 3.11 de calico pour utiliser la commande issue du site de "calico" lui-même. Lorsqu’on ouvre le fichier yaml associé, celle-ci renvoie vers la version 3.13.3 de calico.

Cette dernière s’est déployée sans soucis
Cet exemple montre bien la difficulté de Kubernetes concernant son évolution et le suivi des versions. L’écosystème change tout le temps et si le faite de segmenter chaque composant offre une grande souplesse de configuration, il oblige à être très vigilant sur l’association des briques entre elles. En quelques semaines, des assemblages qui fonctionnaient peuvent ne plus être opérationnels si l’un des composants a été mis à jour. C’est pourquoi les offres de Kubernetes managées, notamment les solutions proposées par les clouds provider public peuvent présenter un intérêt certain. Si elles imposent un cadre d’utilisation (et un coût), elles permettent aux administrateurs de s’affranchir des problématiques de matrice de compatibilité et simplifient grandement le suivi des mises à jour !
N’hésitez pas également à faire un tour dans le menu Compléments pour connaitre le moyen de faire un raz de son cluster. Il m’est arrivé à plusieurs reprise de me tromper et de vouloir repartir de zero, mais attention si on ne fait pas le ménage correctement, toutes les tentatives de reinstallation peuvent se solder par un échec.
Enfin, j'ai intégré la préparation des fichiers de configuration et les prérequis dans un playbook ansible qui reprend également des élements de l'étape 2. Il est téléchargeable ici si besoin (attention à adapter à vos ressource et votre inventaire)