Exemple de définition d'architecture pour Kubernetes (v2)
Avant de se lancer tête baissée dans l’expérimentation, tentons de définir la cible et les briques techniques à mettre en oeuvre.
Schéma d'architecture K8S
Un bon schéma valant mieux qu’un grand discours, voici une rapide présentation de ce que je souhaiterais mettre en oeuvre.
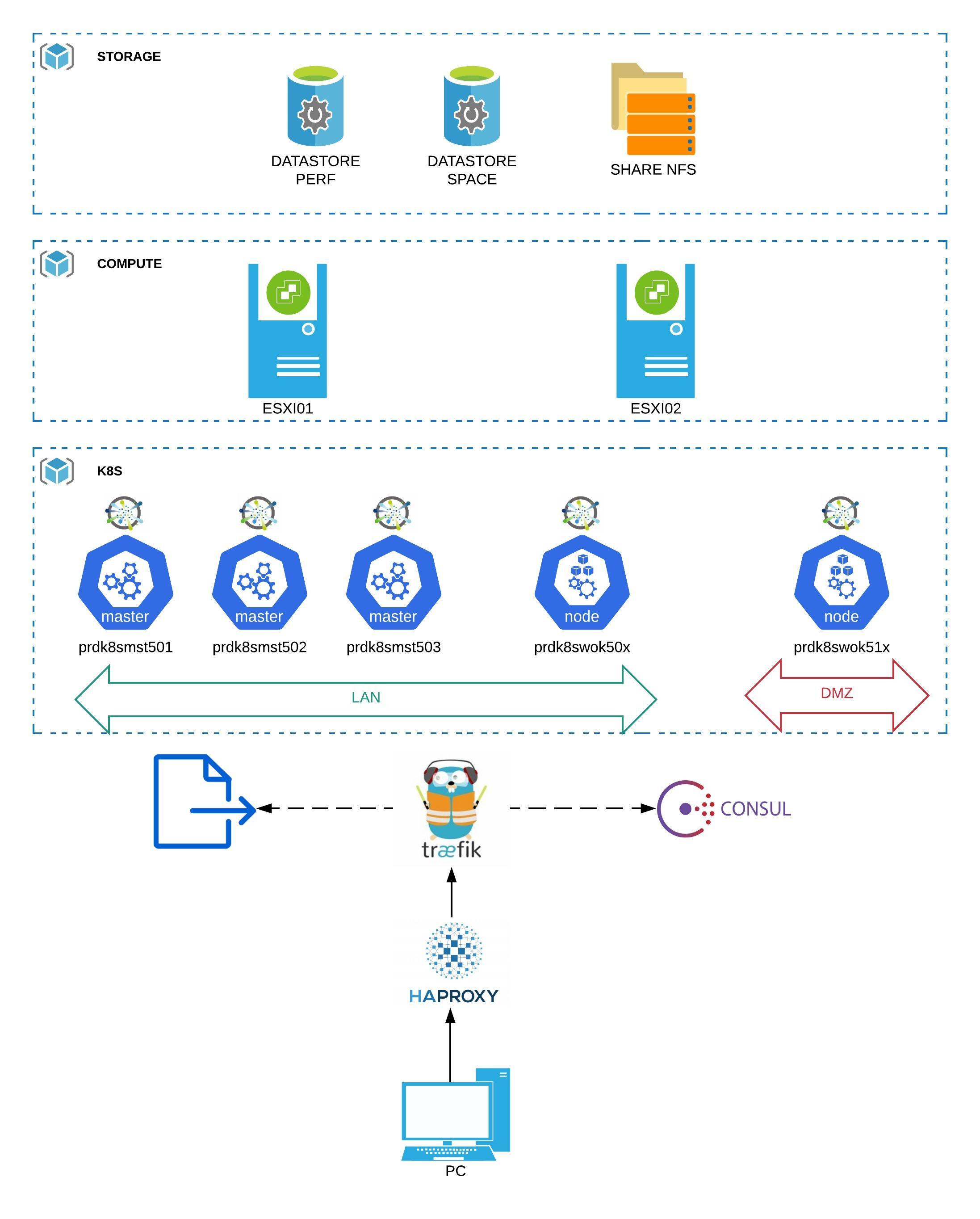
Description des éléments
Traitement de la couche stockage
Je souhaiterais exploiter trois types de solutions:
- Datastore PERF : un espace dédié à la performance exploitant des disques flash sous forme d’un datastore traditionnel vmware formaté en VMFS. Il a pour rôle de fournir un hébergement pour des besoins de performances avec un accès type lecture/écriture depuis une seule source. Un exemple type de cet usage est le stockage des datas et des logs d’une base de données SQL. Concrètement sur le lab, pour simuler cet usage j’utiliserais un SSD local sur un serveur ESXi
- Datastore SPACE : un espace dédié à l’espace exploitant des disques standards sous forme d’un datastore traditionnel vmware. Il a pour rôle de fournir un hébergement pour des besoins d’espace avec un accès type lecture/écriture depuis une seule source. Un exemple type de cet usage est le stockage des binaires d’une application. Concrètement sur le lab, pour simuler cet usage j’utiliserai un partage NFS réalisé depuis un NAS "Synologie" monté comme un datastore vmware
- Un partage NFS: un espace dédié à des accès type lecture/écriture depuis plusieurs sources ou des accès type lecture depuis plusieurs sources. Un exemple type de cet usage est le stockage des fichiers statiques d’un site web. Concrètement sur le lab, pour simuler cet usage j’utiliserai un partage NFS réalisé depuis un NAS synologie .
Traitement de la couche compute
Traitement de la couche network
Kubernetes fonctionne sous forme de "briques" qu'il faut assembler pour avoir un cluster fonctionnel. Les binaires de bases de K8S sont centrés sur l'orchestration des conteneurs. Pour les fonctionnalités tierces comme le moteur d'exécution des conteneurs, leur stockage ou leur communication entre eux, Kubernetes laisse le choix d'adopter les technologies de son choix. Ces briques annexes peuvent être confiées à des solutions tiers à partir du moment ou elles respectent un certain standard et se plient à des normes communes. Concernant le réseau, Kubernetes propose la spécification "CNI" pour "Container Network Interface". Différentes solutions ou "plugins" se basent sur "CNI" pour traiter la couche réseau au sein d'un cluster K8S. À chacun de choisir le plug-in qu'il souhaite fonction des caractéristiques qu'il propose : protocole de routage pris en charge, possibilité d'exploiter des politiques d'accès....Me concernant si pendant un temps, j'avais choisi "Calico", j'ai finalement porté mon choix sur "Antrea", mais nous évoquerons ce point plus tard.
Histoire d'avoir une architecture plus représentative de la réalité, je vais également essayer de dédier des noeuds de traitement à des applications en DMZ. j'avoue que sur ce point, j'ai du mal à me faire une idée. Sur le principe Kubernetes est censé offrir un cluster dans lequel on peut encapsuler toutes ses applications et gérer avec précision leur déploiement tout en contrôlant leur trafic avec différents niveaux d'isolation (sous condition qu'on les paramètre). Je vais donc pousser ce concept jusqu'au bout en mixant au sein d'un même cluster, des noeuds sur mon réseau interne et des noeuds en DMZ. Certains risquent de trouver cela dangereux, et préfèreraient certainement dédier un cluster pour le LAN et un cluster pour la DMZ. Je comprends parfaitement cette préférence, mais dans mon cas, je n'ai pas le luxe de pouvoir multiplier les VMs (nouveau cluster signifie nouveau master)Traitement de la couche Kubernetes
À l'origine, dans la première version de mon cluster, j'étais parti sur l'usage d'Ubuntu 20.04. J'ai pu arriver à une solution pleinement opérationnelle, mais disposant de ressources limitées (2 ESXi seulement) je préférerais maintenant optimiser mon cluster en me basant sur la distribution vmware open source "PhotonOS". À l'image d'autres systèmes dédiés à l'exécution des conteneurs, "PhotonOS" propose une base minimaliste et donc à la fois moins gourmande en ressource et également plus sécurisée, car "nettoyée" des composants superflux pour le bon fonctionnement des conteneurs. Étant donné qu'elle est proposée par Vmware elle dispose également d'un kernel optimisé pour tourner sur un ESXi (mais on peut très bien l'utiliser ailleurs, notamment sur RPI).
À l'heure de la rédaction de l'article, la version 4.0 de PhotonOS est disponible en GA, elle est donc très récente, mais je préfère partir sur la dernière release et m'assurer une certaine pérennité de ma plateforme. Pour la petite anectode, toutes les appliances vmware comme le vcenter par exemple, tournent désormais sous "PhotonOS".
Mon cluster Kubernetes sera composé dans un premier temps d'un noeud master, d'au moins 2 noeuds Worker sur le LAN et d'au moins 2 noeuds Worker en DMZ.
Les noeuds masters sont essentiels au bon fonctionnement du cluster. Ils vont héberger le serveur API sans lequel il est impossible d’interagir avec le cluster et de nombreux autres rôles critiques. Ils vont aussi stocker la base clef/valeur ETCD dans laquelle toute la configuration du cluster va être stockée. On voit beaucoup d’exemples où l’on exploite un seul master. C’est une très bonne chose pour se former ou pour traiter des environnements non critiques, mais sur des contraintes de production on ne peut se contenter que d’un seul master, car si celui-ci venait à tomber, on impacterait l'interaction avec le Cluster. Avoir un master indisponible ne rend pas les applications déjà en oeuvres sur le cluster inopérantes, par contre il n'y a plus d'orchestration et il devient impossible d'opérer son cluster.
C'est pourquoi, si dans une première phase je débuterais avec un seul master, une étape supplémentaire sera réalisée plus tard pour augmenter le nombre de masters. Cela permettra de décrire les opérations à réaliser pour cela, car si je me suis rendu compte qu'on trouve beaucoup d'aide pour ajouter un worker à son cluster, c'est moins le cas avec le master.
À savoir que deux masters n’est pas supporté pour offrir une solution de HA, car c’est insuffisant pour offrir un consensus de l’état du cluster, un troisième master est obligatoire pour permettre à l’ensemble des masters de se mettre d’accord entre eux. Le petit schéma si dessous sera plus parlant.
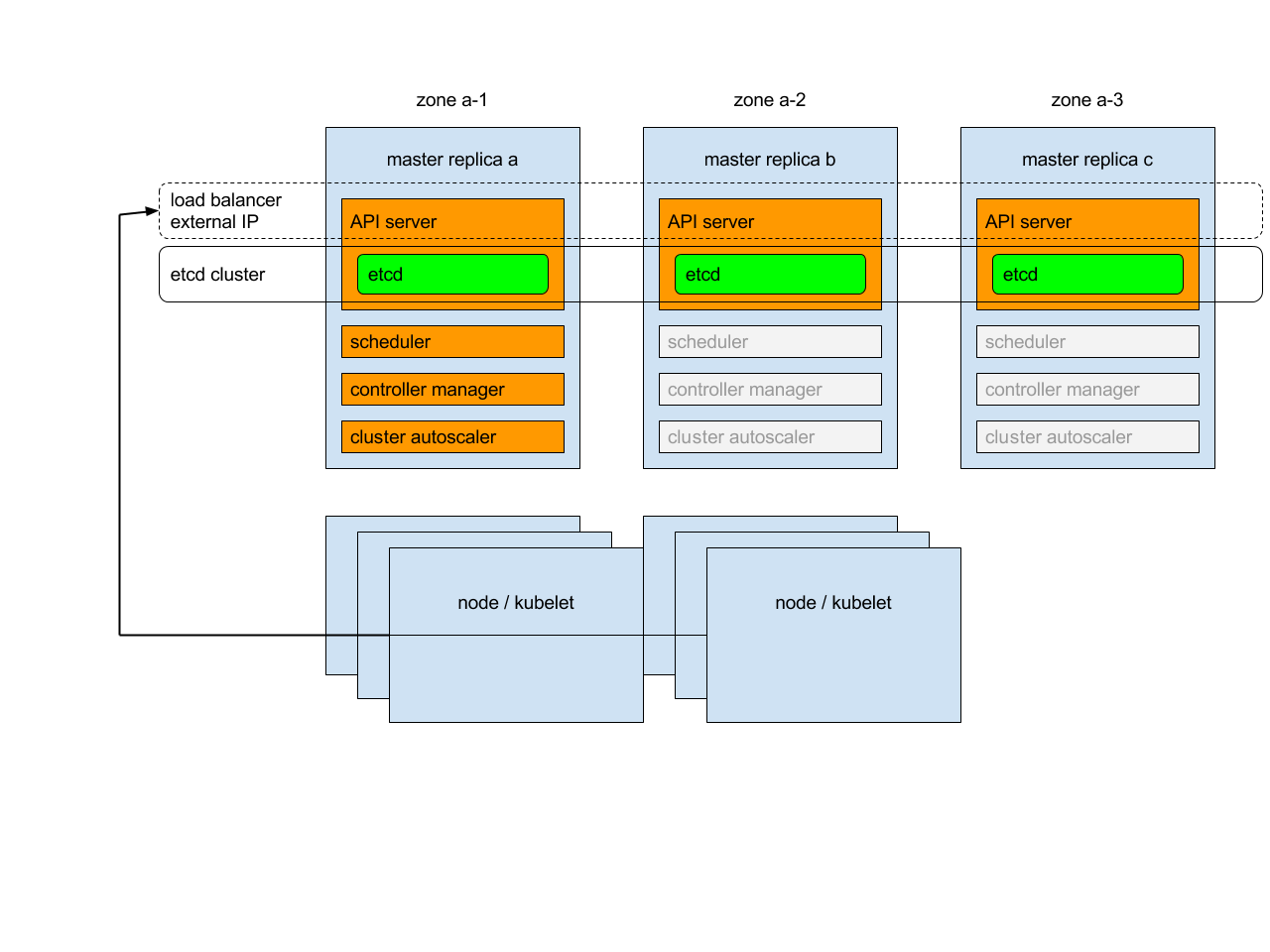
Je vous invite d'ailleur à prendre connaissance de l'article dont est tirée cette illustration et qui explique le principe de HA pour Kubernetes
Cas des applications tierces
Il est plutot conseillé de faire appel à des contrôleurs “Ingress”. Ce sont des composants que l’on déploie sur le cluster et qui vont offrir “un équilibrage de charge, une terminaison TLS et un hébergement virtuel basé sur un nom” (definition officielle). Plusieurs produits sont disponibles, personnellement j’ai retenu “Traefik”. C’est une solution OpenSource, française et très appréciée de la communauté.
Traefik va pouvoir se configurer de différentes manières. La première est par l’intermédiaire de “Kubernetes” lui même puisque Traefik va pouvoir interroger le statut des objets au sein du cluster pour fournir la connectivité adéquate. Je souhaite lui ajouter deux autres sources de configuration. La seconde serait donc l’appel à des fichiers de configuration, la troisième serait l’usage de la solution clef/valeur Consul . L’usage de fichier à plat me permettrait d’ajouter des éléments de configurations peu enclin à bouger. “Consul” présente l’intérêt de fournir une interface graphique simple, mais efficace qui me permettrait de compléter une configuration très rapidement et très facilement sous forme de mots clefs associés à une valeur reconnue par traefik. Enfin, “HAproxy” serait utilisé en frontal du cluster Kubernetes et donc externe à ce dernier (1 VM spécifique) pour assurer un load balancing de niveau 3 uniquement . Dans un cas de prodution, on pourrait imaginer deux instance de HAProxy se partageant une adresse IP virtuelle (VIP) via le protocole VRRP, mais encore une fois mon infra homelab n'est pas extensible à l'infini.
Cette logique serait à reproduire deux fois, l'une pour le LAN, l'autre pour la DMZ.
Il est important de noter que le plus souvent, on parle d'un cluster Kubernetes déployé chez un cloud provider, car plus simple à mettre en oeuvre. Dans ces exemples, la publication des applications à l'extérieur du cluster est le plus souvent traitée dans l'offre du cloud provider. En effet, ces derniers exploitent la notion de "LoadBalancer" des services Kubernetes qui permet d'autoconfigurer les fonctionnalités d'équilibrage de charge du provider.