Mise en place de la couche CPI/CSI vSphere
Comme expliqué dans l’étape 3, il est maintenant conseillé d’utiliser la couche “CNS” soit “Cloud Native Storage” pour l’exploitation du stockage provisionné sous vSphere par Kubernetes.
Étant donné que dans l’étape précédente, le cluster a été déployé en tenant compte de ce point, je vais maintenant configurer l’intégration de K8S avec vSphere.
Je vais reprendre le tutorial suivant en essayant d’exploiter une version plus récente de Kubernetes et intégrer d'autres modifications.
Déploiement de l’interface vSphere Cloud Provider (CPI)
Création du fichier de configuration
Il faut créer un fichier de configuration "vsphere.conf " qui va décrire les éléments vSphere. Son contenu est le suivant:
[Global]
port = "443"
insecure-flag = "true"
secret-name = "cpi-global-secret"
secret-namespace = "kube-system"
[VirtualCenter "vcenter.coolcorp.priv"]
datacenters = "Paris"
Les options sont assez explicites. La section "Global" va s’appliquer à tout les venter auquel Kubernetes peut se connecter. Il est ensuite possible pour chaque vCenter de surcharger sa configuration.
Attention au nom donné au champ "secret-name", car il faudra bien prendre soin d’utiliser le même par la suite, lorsque je vais créer l'objet secret K8S correspondant.
Je génère un objet Kubernetes type "configmap" pour stocker le contenu de ce fichier de configuration.
kubectl create configmap cloud-config --from-file=vsphere.conf --namespace=kube-system
Création de l'objet secret pour l'accès au vCenter
Il faut maintenant générer un objet "secret" via le fichier "yaml cpi-engineering-secret.yaml" qui va contenir le login et le mot de passe du compte de service que j’ai déclaré dans le fichier de configuration précédent. C’est ce compte qui va être utilisé pour interagir avec l’infrastructure vSphere (dont j'ai donné les droits sur le vCenter en étape 3).
apiVersion: v1
kind: Secret
metadata:
name: cpi-global-secret
namespace: kube-system
stringData:
vcenter.coolcorp.priv.username: "svc_k8s_vcp@coolcorp.priv"
vcenter.coolcorp.priv.password: "monmodepasse"
kubectl create -f cpi-engineering-secret.yaml
L’objet secret étant chiffré au sein du cluster, cela va garantir la sécurité des identifiants du compte associé. Attention, en fonction des versions des fichiers yaml publiées par vmware , il se peut que le secret porte le nom de "vcenter-secret" à la place de cpi-global-secret.
Déploiement des objets liés au "cloud controller manager"
Il faut ensuite utiliser les fichiers yaml fournis par vmware pour la création des ressources Kubernetes nécessaires.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-roles.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-role-bindings.yaml
kubectl apply -f https://github.com/kubernetes/cloud-provider-vsphere/raw/master/manifests/controller-manager/vsphere-cloud-controller-manager-ds.yaml
Je contrôle que le déploiement c’est passé correctement et que tous les pods sont "Running"
kubectl get pods --namespace=kube-system
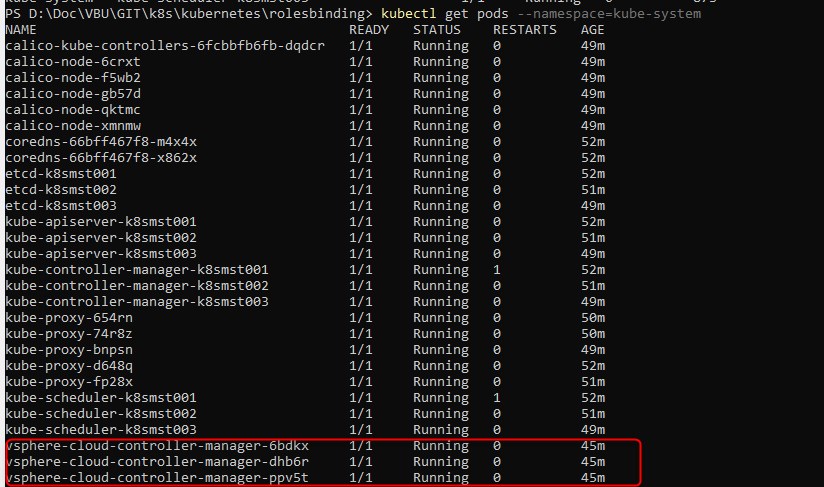
Cela ne suffit pas pour s’assurer que tout fonctionne. Il va être nécessaire de lire les logs de chaque conteneur associés aux pods vsphere-cloud-controller
kubectl logs vsphere-cloud-controller-manager-ppv5t --namespace=kube-system
Il faut obtenir sur l’un ou l’autre des contrôleurs une sortie de ce type
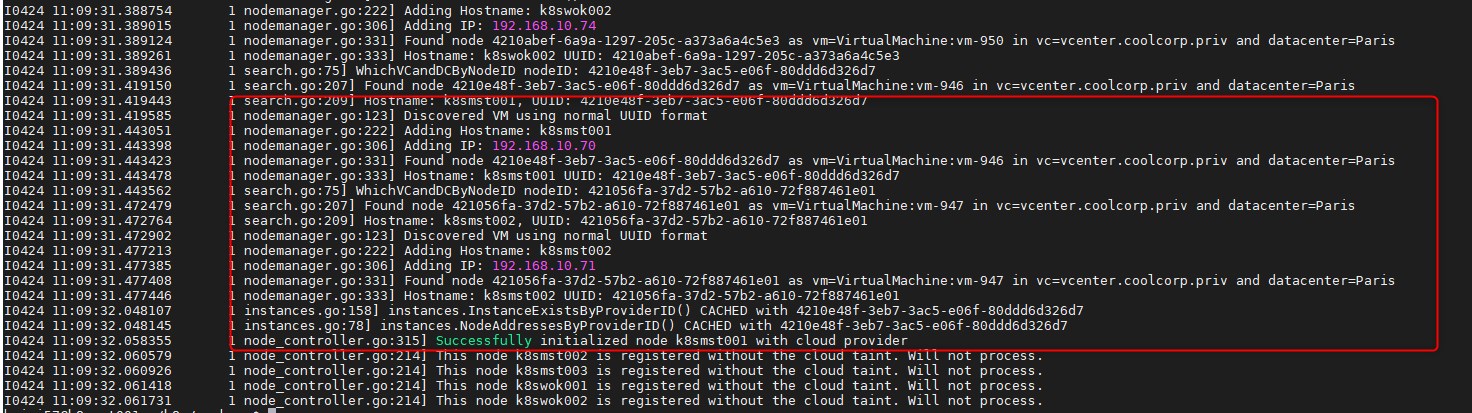
Cela signifie que les VMs associées au noeud K8S ont été identifiées et que la communication avec le vCenter est opérationnelle . (cela peut durer quelques minutes)
La commande suivante:
kubectl describe nodes | grep "ProviderID"
doit confirmer que le provider vSphere est bien associé au cluster.

update 04/05/2020: Si comme sur la capture ci-dessus, vous n'observez qu'un seul retour suite à la commande, alors c'est que le provider vSphere n'a été déployé que sur un noeud. Vous devriez avoir autant de ligne que de noeuds.
Si ce n'est pas le cas, alors supprimez l'installation du provider
kubectl delete -f https://github.com/kubernetes/cloud-provider-vsphere/raw/master/manifests/controller-manager/vsphere-cloud-controller-manager-ds.yaml
kubectl delete -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-role-bindings.yaml
kubectl delete -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-roles.yaml
Tapez la commande suivante :
kubectl describe nodes | egrep "Taints:|Name:"

Tout les noeuds devrait avoir l'option "node.cloudprovider.kubernetes.io/uninitialized=true:NoSchedule". Si ce n'est pas le cas, alors forcer le parametre avec la commande
kubectl taint nodes nom_du_noeud node.cloudprovider.kubernetes.io/uninitialized=true:NoSchedule
Vous pouvez ensuite à nouveau lancer le déploiement du provider
kubectl apply -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-roles.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes/cloud-provider-vsphere/master/manifests/controller-manager/cloud-controller-manager-role-bindings.yaml
kubectl apply -f https://github.com/kubernetes/cloud-provider-vsphere/raw/master/manifests/controller-manager/vsphere-cloud-controller-manager-ds.yaml
En tapant à nouveau la commande kubectl describe nodes | grep "ProviderID" vous devriez avoir cette-fois autant de ligne que de noeuds.

Pour la petite histoire, la commande "kubectl taint" permet d'appliquer une contrainte sur un node. Cela permet d'empêcher un pod qui ne tolérait pas cette contrainte de s'exécuter sur le noeud. Il semblerait que lors du déploiement du provider vSphere, celui-ci ne s'applique que si le noeud dispose du "taint" node.cloudprovider.kubernetes.io/uninitialized à true. Une fois le provider installé celui-ci retire le "taint". Normalement le fait d'avoir initilialié les nodes avec l'option "cloud provider external" lors du déploiement du cluster K8S aurait du positionner cette contrainte "taint" automatiquement, mais il semble que parfois...non :)
Déploiement CSI
Création du fichier de configuration
Je crée un fichier de configuration appelé csi-vsphere.conf avec le contenu suivant:
[Global]
cluster-id = "CLU"
[VirtualCenter "vcenter.coolcorp.priv"]
insecure-flag = "true"
user = "svc_k8s_vcp@coolcorp.priv"
password = "monmotdepasse"
port = "443"
datacenters = "Paris"
Il reprend le compte de service créer dans l’étape précédente
Création du secret pour l'accès au vCenter
Ce fichier me permet de générer un objet "secret" que j’appelle "vsphere-config-secret"
kubectl create secret generic vsphere-config-secret --from-file=csi-vsphere.conf --namespace=kube-system
Déploiement des objets liés au controleur CSI
Il faut maintenant utiliser les fichiers de déploiement fourni par vmware. Malheureusement les liens du tutoriaux ne fonctionnent plus au moment de la rédaction de l’article. Je me suis donc basé directement sur le repo GIT du projet.
Je vous les propose également en téléchargement, mais n’hésiter pas à jeter un œil au repo pour voir si une version plus récente n’est pas disponible.
update 04/05/2020
La partie barrée ci-dessous n'est normalement plus à appliquer. Je la conserve tout de même au cas ou, mais vous ne devriez pas en avoir besoin.
En passant de l’add-on réseau "Flannel" lors de mes premiers essais à "Calico", j’ai du modifier le fichier "vsphere-csi-controller-ss.yaml" en ajoutant l’option hostNetwork: true et en commentant l’option #dnsPolicy: "Default"
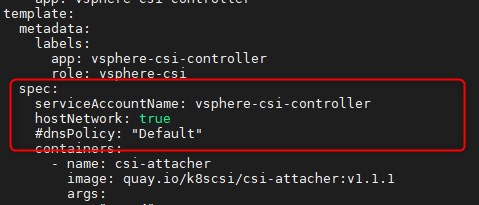
Je n’ai pas l’explication exacte, mais lorsqu’on regarde le log du conteneur "vsphere-csi-controller" du pod "vsphere-csi-controller-0" qui est déployé avec le fichier "vsphere-csi-controller-ss.yaml", on s’aperçoit qu’il cherche à communiquer directement avec le vCenter. Or par défaut le conteneur est isolé au sein du cluster, j’ai donc dû l’autoriser à exploiter l’IP du noeud K8S pour communiquer directement avec le vCenter. J’aurai imaginé que le contrôleur CSI passe par le contrôleur CPI déployé juste avant, et qui lui est configuré par défaut pour utiliser l’IP du noeud. Mais avec le passage à "Calico", il y’a du avoir un changement quelque part.
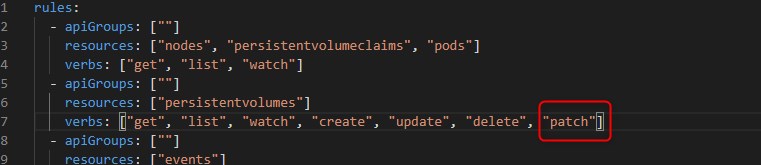
Attention au yaml vsphere-csi-controller-rbac.yaml.
Le case suivant indique qu'il peut manquer un mot clef pour une règle. Si vous récuperez les yaml directement depuis mon site, la modification est déja faite mais sinon assurez vous d'avoir bien le mot "patch" pour les "persistentvolumes"
On applique donc les trois yaml
kubectl apply -f vsphere-csi-controller-rbac.yaml
kubectl apply -f vsphere-csi-controller-ss.yaml
kubectl apply -f vsphere-csi-node-ds.yaml
Cela a comme conséquence la création de nouveaux pods
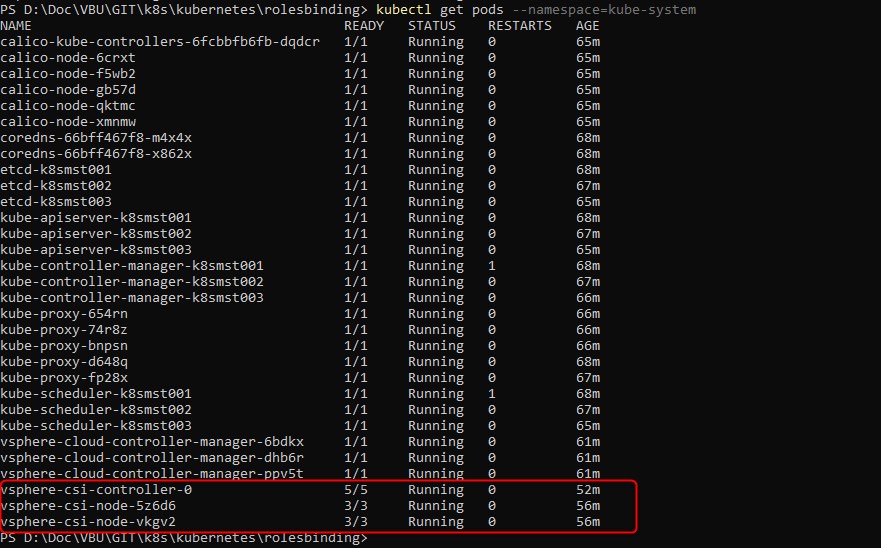
Controle de l'installation et vérifications
Il reste maintenant à contrôler le bon fonctionnement de l’ensemble
Création d'une classe de stockage
Je crée donc d’abord un fichier de "storageclass" dont le contenu est le suivant
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: vsphere-dts-ssd
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.vsphere.vmware.com
allowVolumeExpansion: true
reclaimPolicy: Delete
parameters:
#storagepolicyname: "VMW_K8S_SSD"
datastoreurl: ds:///vmfs/volumes/5e179fa4-b8a6bbc6-80e3-001b219adf10/
Je lui indique comme cible de stockage le chemin de mon datastore vmware que je souhaite associer à cette classe de stockage. Je pourrais également utiliser un tag que j’aurai au préalable associé à mon datastore depuis l’interfarce de vCenter . Cela peut permettre d’associer plusieurs datastores aux caractéristiques identiques à une classe de stockage (semble fonctionner uniquement avec vsan).
kubectl.exe apply -f vsphere-storageclass-volume-ssd-readwrite.yml
Création d'un objet PersistentVolumeClaim
Je créer ensuite un objet PersistentVolumeClaim que je vais configurer pour qu’il puisse provisionner un volume de 1Gi dans la classe que je viens de créer juste avant et qui correspond à mon datastore vmware.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: k8s-psvc-vsphere-ssd
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: vsphere-dts-ssd
kubectl.exe apply -f vsphere-persistent-volume-ssd-rwonce-example.yml
J’observe bien la création du volume dans vCenter

J’ai donc bien une communication fonctionnelle entre mon cluster K8S et vCenter. Je peux donc associer des volumes à mes pods en cas de besoin de volumes persistents. Je peux jouer sur les classes de stockage pour associer deux types de datastore l’un plutôt orienté performance et l’autre plutôt espace, comme souhaité à l’étape 1.