A propos
Cette article a été archivé. Un nouvelle version de ce dernier est disponible ici
Exemple de définition d'architecture pour Kubernetes
Avant de se lancer tête baissée dans l’expérimentation, tentons de définir la cible et les briques techniques à mettre en oeuvre.
Schéma d'architecture K8S
Un bon schéma valant mieux qu’un grand discours, voici une rapide présentation de que je souhaiterais mettre en oeuvre.
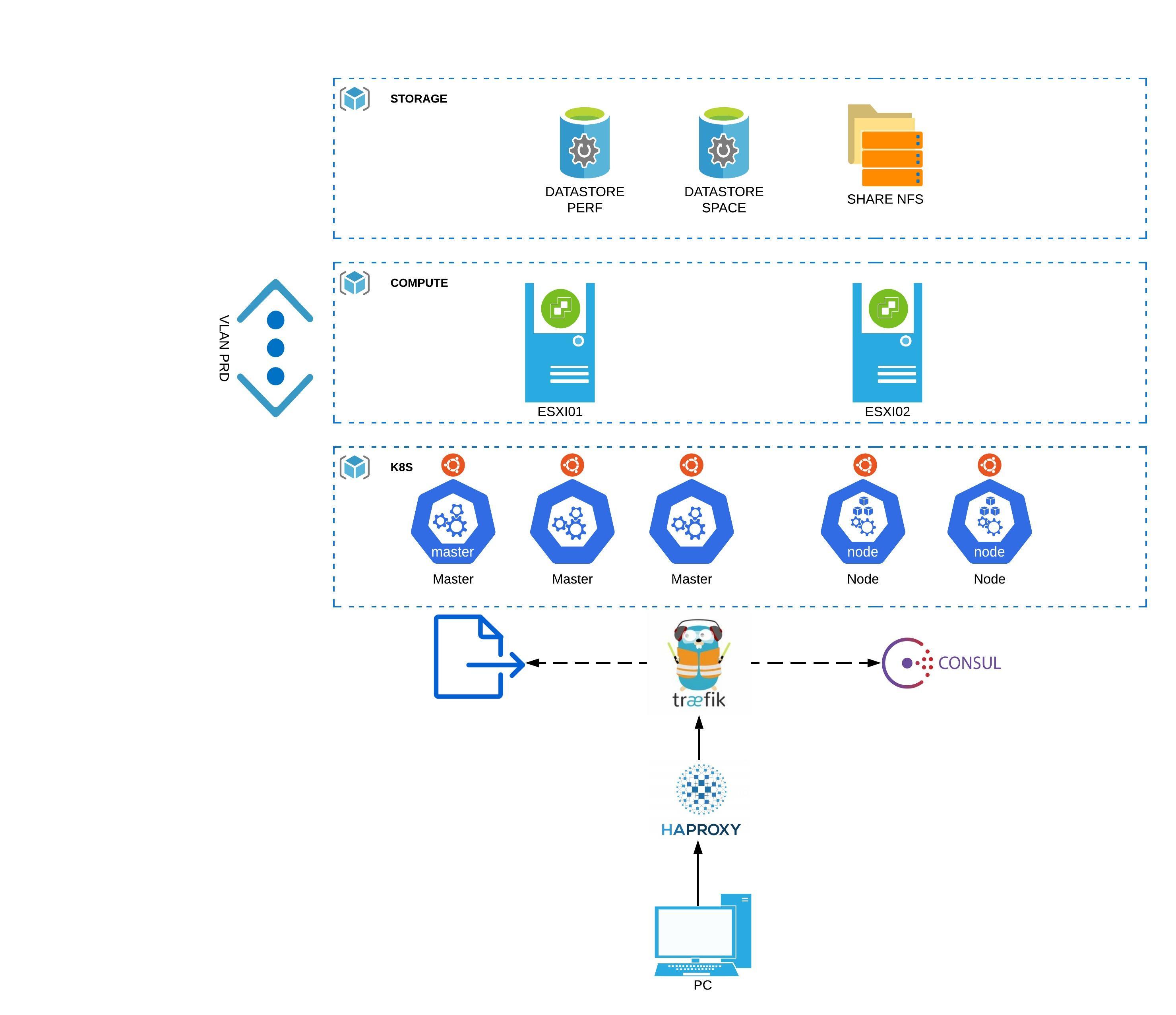
Description des éléments
Traitement de la couche stockage
Je souhaiterais exploiter trois types de solutions:
- Datastore PERF : un espace dédié à la performance exploitant des disques flash sous forme d’un datastore traditionnel vmware formaté en VMFS. Il a pour rôle de fournir un hébergement pour des besoins de performances avec un accès type lecture/écriture depuis une seule source. Un exemple type de cet usage est le stockage des datas et des logs d’une base de données SQL. Concrètement sur le lab, pour simuler cet usage j’utiliserais un SSD local sur un serveur ESXi
- Datastore SPACE : un espace dédié à l’espace exploitant des disques standards sous forme d’un datastore traditionnel vmware. Il a pour rôle de fournir un hébergement pour des besoins d’espace avec un accès type lecture/écriture depuis une seule source. Un exemple type de cet usage est le stockage des binaires d’une application. Concrètement sur le lab, pour simuler cet usage j’utiliserai un partage NFS réalisé depuis un NAS "Synologie" monté comme un datastore vmware
- Un partage NFS: un espace dédié à des accès type lecture/écriture depuis plusieurs sources ou des accès type lecture depuis plusieurs sources. Un exemple type de cet usage est le stockage des fichiers statiques d’un site web. Concrètement sur le lab, pour simuler cet usage j’utiliserai un partage NFS réalisé depuis un NAS synologie .
Traitement de la couche compute
J’utiliserais deux serveurs ESXi 6.7 pour héberger la totalité des VMs nécessaires au lab. A l'heure de la rédaction de ce document la version 7.0 est disponible et inclut un support natif de Kubernetes, mais les retours d'experiences sont peu nombreux pour l'instant. Dans un contexte plus réaliste, il y'a de forte chance que la version 6.7 soit davantage utilisé dans un premier temps au vu du parc actuellement déployé.
Traitement de la couche network
Sans doute la partie la moins ambitieuse du lab, je souhaiterais partir au plus simple en exploitant dans un premier temps un seul et unique VLAN sur un seul subnet. Je ferais peut être évoluer ce point si déjà j’arrive au bout du lab dans sa version première.
Traitement de la couche Kubernetes
Tous les noeuds Kubernetes seront des VMs sous Ubuntu Server 19.10. Je pourrais utiliser des distributions spécialisées pour ne faire tourner que des conteneurs avec une empreinte la plus légère possible comme “PhotonOS” ou “CoreOS”. Je préfère me simplifier l’expérience en utilisant des versions plus “standart” d’un système. Ubuntu server est l’une des distributions les plus utilisées pour un peu tous les usages dans l’univers Linux. La version 18.04 incluant un support longue durée serait sans doute plus pertinente dans un cas de production , mais je voudrais utiliser les versions les plus récentes des packages au moment de mes essais.
update 18/05/2020: Je suis passé en version Ubuntu 20.04. Aucun soucis rencontré. Vous pouvez donc utiliser cette version LTS si besoin.
Mon cluster Kubernetes sera composé de 3 noeuds master et 2 noeuds Worker. Les noeuds masters sont essentiels au bon fonctionnement du cluster. Ils vont héberger le serveur API sans lequel il est impossible d’interagir avec le cluster et de nombreux autres rôles critiques. Ils vont aussi stocker la base clef/valeur ETCD dans laquelle toute la configuration du cluster va être stockée. On voit beaucoup d’exemples où l’on exploite un seul master. C’est une très bonne chose pour se former ou pour traiter des environnements non critiques, mais sur des contraintes de production on ne peut se contenter que d’un seul master, car si celui-ci venait à tomber, on impacterait très fortement le bon fonctionnement du cluster. Deux master n’est pas supporté pour offrir une solution de HA, car c’est insuffisant pour offrir un consensus de l’état du cluster, un troisième master est obligatoire pour permettre à l’ensemble des masters de se mettre d’accord entre eux. Le petit schéma si dessous sera plus parlant.
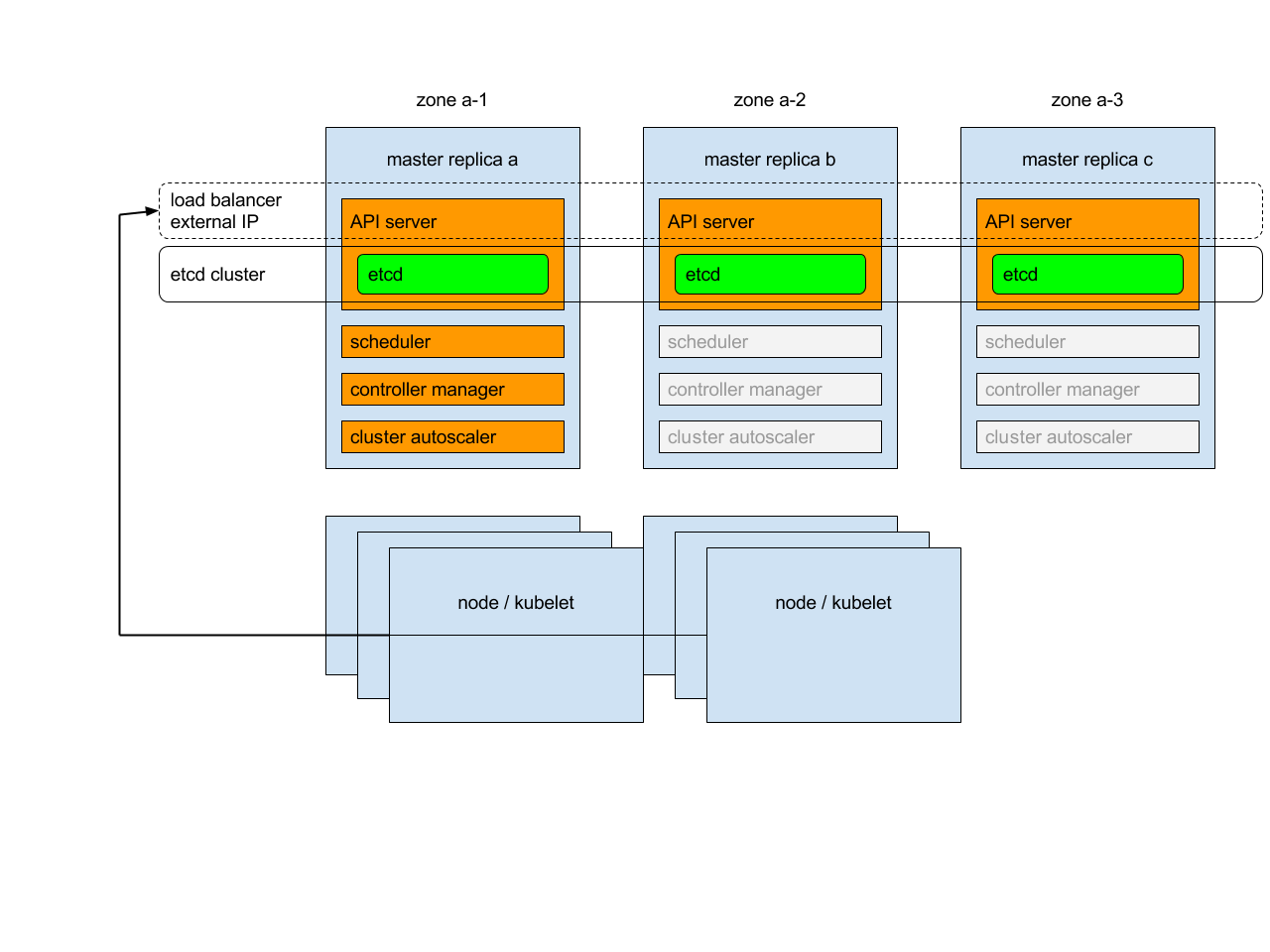
Je vous invite d'ailleur à prendre connaissance de l'article dont est tiré cette illustration et qui explique le principe de HA pour Kubernetes
J’utiliserai 2 noeud worker. On pourrait imaginer en avoir plus puisque ce sont eux qui concrètement vont faire tourner les applications, mais ça reste un lab… et je n’ai pas des ressources infinies sur ma petite infra homemade.
Cas des applications tierces
L’une des difficultés que je rencontre avec Kubernetes, c’est la capacité à exposer les applications qui y sont hébergées à l’extérieur du cluster. De base, c’est une fonctionnalité, qui si elle est possible nativement, n’est pas très optimisée et assez contraignante.
Il est plutot conseillé de faire appel à des contrôleurs “Ingress”. Ce sont des composants que l’on déploie sur le cluster et qui vont offrir “un équilibrage de charge, une terminaison TLS et un hébergement virtuel basé sur un nom” (definition officielle). Plusieurs produits sont disponibles, personnellement j’ai retenu “Traefik”. C’est une solution OpenSource, française et très appréciée de la communauté.
Traefik va pouvoir se configurer de différentes manières. La première est par l’intermédiaire de “Kubernetes” lui même puisque Traefik va pouvoir interroger le statut des objets au sein du cluster pour fournir la connectivité adéquate. Je souhaite lui ajouter deux autres sources de configuration. La seconde serait donc l’appel à des fichiers de configuration, la troisième serait l’usage de la solution clef/valeur Consul .L’usage de fichier à plat me permettrait d’ajouter des éléments de configurations peu enclin à bouger. “Consul” présente l’intérêt de fournir une interface graphique simple, mais efficace me permettrait de compléter une configuration très rapidement et très facilement sous forme de mots clefs associés à une valeur reconnue par traefik.
Enfin, “HAproxy” serait utilisé en frontal du cluster Kubernetes et donc externe à ce dernier (1 VM spécifique) pour assurer un load balancing de niveau 3 uniquement . Dans un cas de prodution, on pourrait imaginer deux instance de HAProxy se partageant une adresse IP virtuelle (VIP) via le protocole VRRP, mais encore une fois mon infra homelab n'est pas extensible à l'infini.