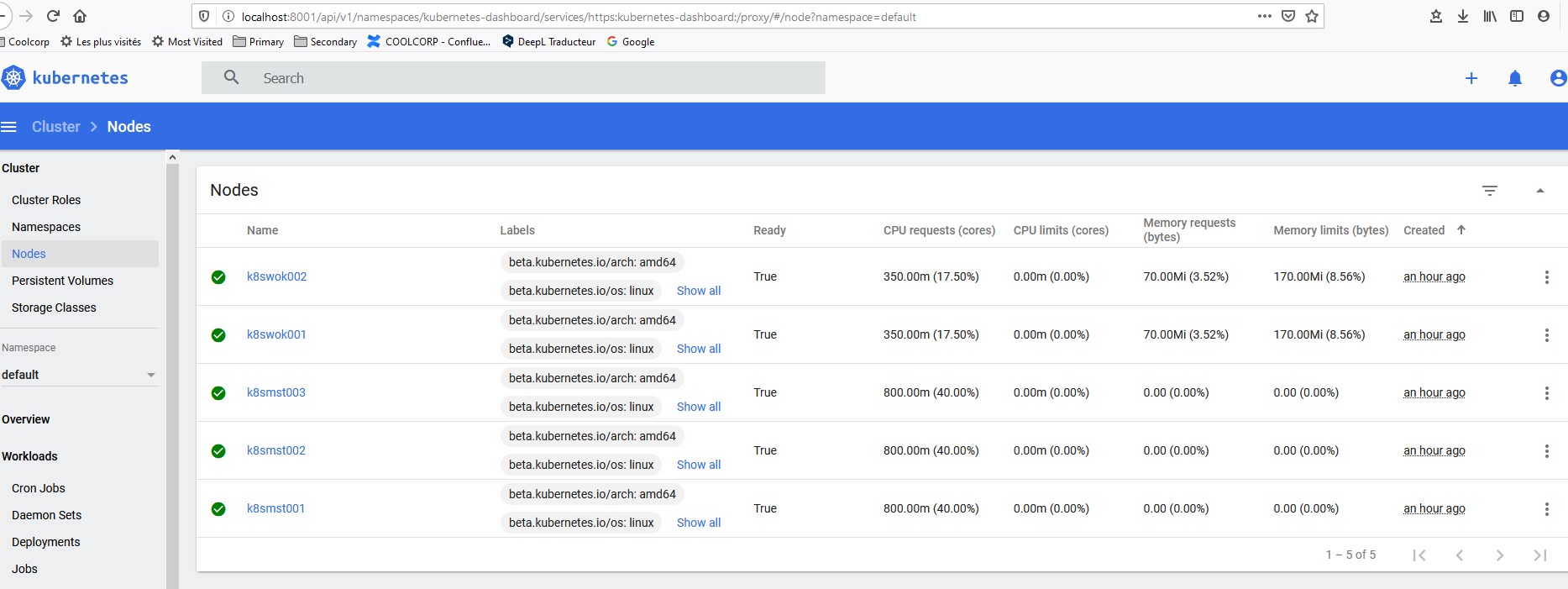
Déploiement du cluster Kubernetes sous vSphere (V2)
Nous arrivons maintenant à une étape
importante et conséquente : la création du cluster Kubernetes.
Encore une fois je vais m’inspirer du tutorial trouvable ici
mais je vais m’en éloigner quelque peu.
Intégration de K8S dans vSphere
Je vais essayer de déployer Kubernetes en préparant l'intégration de la notion de « CNS » soit « Cloud Native Storage » que je configurerais à l'étape suivante. Il s’agit de permettre une communication entre vSphere et Kubernetes pour avoir un provisionnement automatique du stockage. Le tutorial semble utiliser VCP soit « vSphere Storage for Kubernetes », une autre solution toujours utilisée, mais dont il est maintenant conseillé de se détacher pour exploiter « CNS ». Si le sujet vous intéresse, je vous conseille la lecture de cet l’article.
Je vais donc également m’inspirer du tutorial suivant mais en essayant d’utiliser une version plus récente de KubernetesPréparation de l’infrastructure vSphere.
Création du compte de service
Afin de permettre à Kubernetes d’interagir avec vSphere il est nécessaire de créer un compte de service que l’on va déclarer dans l’interface d’un ou des vCenter. De mon côté j’ai choisi la facilité en lui attribuant les droits admin sur toute mon infrastructure de POC.

Configuration HAProxy (VM dediée)
Comme vu précedemment, HAproxy s'installe très facilement via le packet fourni dans le repo de photonOS. Si ce n'est pas déja fait utiliser la commande
tdnf install haproxy
Il va juste être nécessaire de positionner la bonne configuration HAproxy. Pour cela il faut éditer le fichier de configuration /etc/haproxy/haproxy.cfg et ajouter les éléments de configuration suivant:
global
defaults
timeout
client 30s
timeout
server 30s
timeout
connect 30s
frontend k8s_mst
bind
192.168.10.45:6443
default_backend
backend k8s_nodes_master
mode
tcp
option tcp-check
server
prdk8smst501 192.168.10.56:6443 check
Pour l'instant on ne va configurer que l'accès à l'API de kubernetes, la configuration ci-dessus permet donc d'accéder depuis une "vip" au noeud master du cluster. Dans mon cas pour l'instant, il n'y en a qu'un, donc c'est un peu inutile. Mais cela s'avèrera nécessaire quand on ajoutera des noeuds master au cluster, donc autant préparer la configuration dès maintenant
Installation des binaires kubernetes
Sous photonOS, il faut utiliser la commande suivante
tdnf install kubernetes-kubeadm
Cette commande est à taper sur chaque noeud du cluster. Non seulement elle va installer kubeadm mais également les binaires kubelet. À noter que photonOS arrive avec des repos Kubernetes déjà paramétrés. Il s'agit de binaire proposé par vmware et non des repos par défaut de Kubernetes. Il ne s'agit donc pas de la dernière version de l'écosystème K8S, mais il est préférable de retenir la version proposée par photonOS car elle assure une certaine stabilité. Maintenant rien ne vous empêche d'intégrer de nouveaux repos pour avoir la dernière release de K8S à disposition.
Fichier de configuration pour Kubernetes
Son contenu va être le suivant
---
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubeletExtraArgs:
cloud-provider: external
kubernetesVersion: 1.19.7
networking:
podSubnet: "10.1.0.0/16"
serviceSubnet: "10.2.0.0/16"
controlPlaneEndpoint: "kube.coolcorp.priv:6443"
clusterName: "prdk8sclu"
apiServer:
certSANs:
- 192.168.10.45
- kube.coolcorp.priv
Les éléments en rouge correspondent à l'accès à l'api de mon cluster:
- 192.168.10.45 : c’est l’IP de ma VIP gérer par mon loadbalancer HAproxy
- kube.coolcorp.priv : C’est le nom DNS associé à ma VIP qui va pointer vers mon serveur HAProxy

-1.19.7: c’est la version de
Kubernetes que je vais déployer.
Le podSubnet
correspond au réseau IP qui va être associé à mes conteneurs dans mes
pods. Cela implique dans mon cas, que chaque conteneur aura une IP
interne en 10.1.0.0/16. Attention de choisir une plage disponible, car
il existera sur chaque noeud une "gateway" virtuelle liée au driver
réseau antrea (que je déploierais plus tard), il faut donc retenir un
réseau libre sur son infrastructure pour éviter tout conflit de
routage.
Le serviceSubnet sera quant à lui un réseau utilisé par mes objets de type "Service" au sein de mon cluster. De la même manière il est préférable choisir une plage disponible.
Création du cluster
Initialisation du premier noeud master
Je vais maintenant pouvoir créer mon cluster depuis une session root sur mon premier noeud master.
Je lance la commande suivantekubeadm init --config /etc/kubernetes/kubeadm.conf --upload-certs --v=5
(n’oubliez pas –v=5, c’est très pratique en cas d’échec afin d’avoir les détails de l’erreur)Au bout de quelques minutes, le premier nœud est initialisé et j’obtiens en sortie les commandes nécessaires à passer sur les autres nœuds pour les ajouter au cluster (ne tenez pas compte du nom de serveur issu de mon ancienne installation).
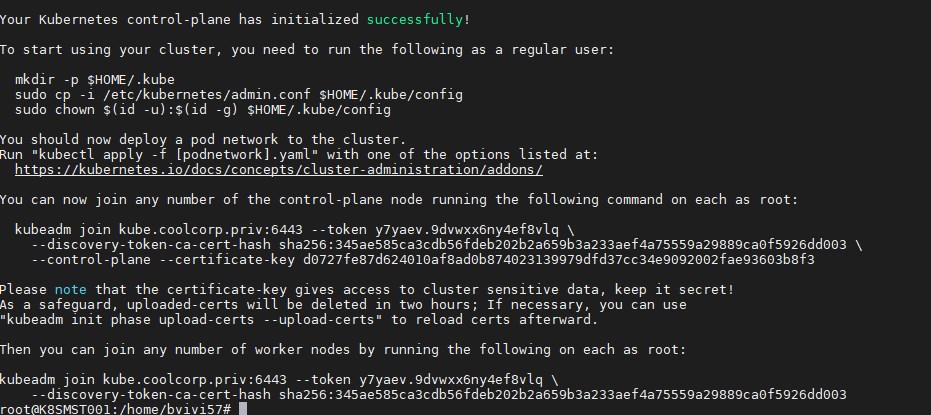
Ajout des noeuds supplémentaires
Arriver à ce stade, il serait possible d'ajouter des noeuds master via la commande suivante
Néanmoins comme déjà expliqué, je ferais cela plus tard dans un article dédié au sujet. Je vais donc me contenter d'ajouter mes noeuds worker. Pour cela, sur chacun d'eux, je tape la commande suivante rapportée par ma sortie de kubeadm.
kubeadm join kube.coolcorp.priv:6443 --token y7yaev.9dvwxx6ny4ef8vlq \
--discovery-token-ca-cert-hash sha256:345ae585ca3cdb56fdeb202b2a659b3a233aef4a75559a29889ca0f5926dd003 \
--control-plane --certificate-key d0727fe87d624010af8ad0b874023139979dfd37cc34e9092002fae93603b8f3
kubeadm join kube.coolcorp.priv:6443 --token y7yaev.9dvwxx6ny4ef8vlq \
--discovery-token-ca-cert-hash sha256:345ae585ca3cdb56fdeb202b2a659b3a233aef4a75559a29889ca0f5926dd003
Récupération de la configuration pour l'accès au cluster K8S
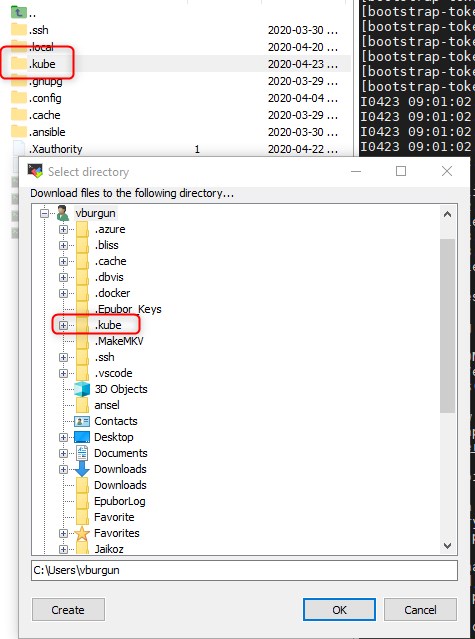
J’obtiens également les commandes nécessaires à la récupération de la configuration de "kubctl" qui va me permettre de piloter mon cluster.
À noter qu’il vous suffira de récupérer le binaire windows "kubectl" et de copier le dossier .kube du noeud K8S dans votre profil utilisateur pour pouvoir piloter votre cluster depuis un poste externe sous Windows.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
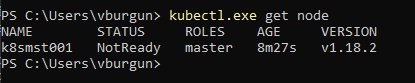
Vérification de l'état des noeuds Kubernetes
On peut d’ailleurs vérifier le
statut du cluster avec la commande kubectl get node
Le noeud est “NotReady”, c’est normal pour l’instant (ne tenez pas
compte de la version et du nom de serveur, c'est une capture issue de ma
précédente installation).
Je vais maintenant ajouter mes autres noeuds en reprenant les commandes
précédents générées à la fin de l’initialisation du cluster.
Attention, les commandes sont a passer dans un context root
Une fois terminé, si je vérifie l’état de mes noeuds j’arrive au
résultat suivant (ne tenez pas compte de la version, ni du nom des
noeuds, la capture est issue de l'ancienne version de mon tutorial)

Tous les noeuds sont dans un état “NotReady”. Ce qui est normal, car je
n’ai pas encore déployé un add-on network. En effet pour que la
résolution DNS interne au cluster fonctionne et que les pods puissent
dialoguer sur l’ensemble du cluster il est nécessaire d’implémenter une
couche réseau. Il en existe plusieurs qui présentent des
caractéristiques différentes et des fonctionnalités spécifiques. C’est à
chacun de choisir ce qui lui semble le plus adapté à ses besoins. Pour
en savoir plus je vous invite à lire l’excellent article suivant
qui détaille les principaux add-on possibles.
Par contre attention, le choix de l’add-on peut avoir des conséquences
sur le déploiement du cluster, notamment sur l’option “podSubnet:” du
fichier de configuration utilisé par kubeadm. De même il peut y’avoir
certains prérequis propres à chaque solution. C’est donc un choix à
faire en amont du déploiement du cluster.
Cas des noeuds en DMZ
De mon côté, j'utilise une solution OPNsense pour filtrer mes zones réseau. Voici les flux que j'ai dû autoriser.
| Sens | Source | Destination | Port et protocole | Raison |
| LAN vers DMZ | Noeud master | Noeud Worker en DMZ | TCP 10250 | Dialogue avec les kubelet depuis le master |
| LAN vers DMZ | Noeud master | Noeud Worker en DMZ | UDP 6081 | Encapsulation Geneve (réseau virtuel) |
| DMZ vers LAN | Noeud Worker en DMZ | Noeud Master en LAN et VIP HaProxy Master | TCP 6443 | Interrogation de l'API depuis les noeuds en DMZ |
| DMZ vers LAN | Noeud Worker en DMZ | Noeud Master en LAN | TCP 10349 | Interrogation du controleur Antrea |
| DMZ vers LAN | Noeud Worker en DMZ | Noeud Master en LAN | UDP 6081 | Encapsulation Geneve (réseau virtuel) |
| DMZ vers LAN | Noeud Worker en DMZ | NAS | TCP 2049 TCP/UDP 111 TCP/UDP 892 |
Accès au storage NFS |
Installation de l'addon réseau pour K8S
Dans mon cas, j’avais débuté par flannel, puis j'avais basculé sur calico pour finalement retenir aujourd'hui antrea.
Antrea est un projet OpenSource maintenu par VMware connaissant de plus en plus d'adeptes. Etant basé sur OpenVswitch, il est cross plateforme Linux/Windows (ce qui pourrait faciliter la mise en place de cluster hybride), il peut tirer parti des fonctionnalités d'accélération hardware de certaines cartes réseau et il fonctionne sur la couche L3 et L4. Il est compatible avec les network policie de Kubernetes et peut être complété d'une CLI et de dashboard sous ELK. Bref, il me convient très bien au vu de ma faible experience sur le sujet.
Déploiement de Antrea
Le déploiement se fait simplement avec la commande
kubectl apply -f https://raw.githubusercontent.com/vmware-tanzu/antrea/main/build/yamls/antrea.yml
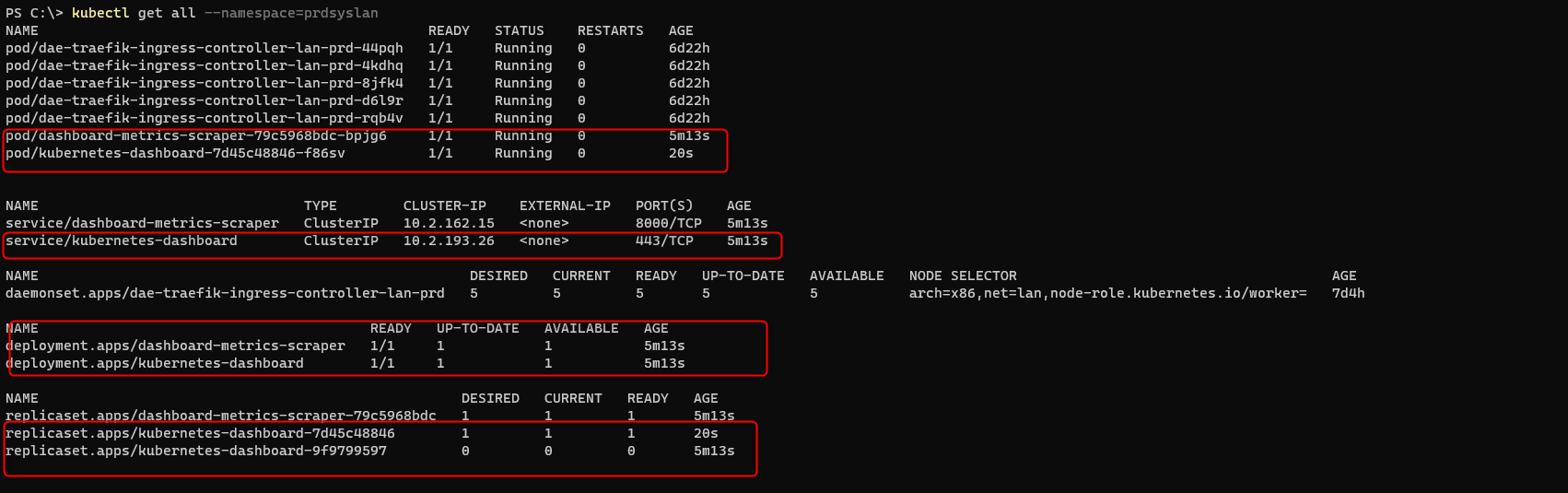
Si je refais un relevé de l’état de mes nodes ils sont maintenant tous à "Ready" (ne tenez pas compte du nom de serveurs et de la version, c'est une capture issue de l'ancienne version du tutorial)

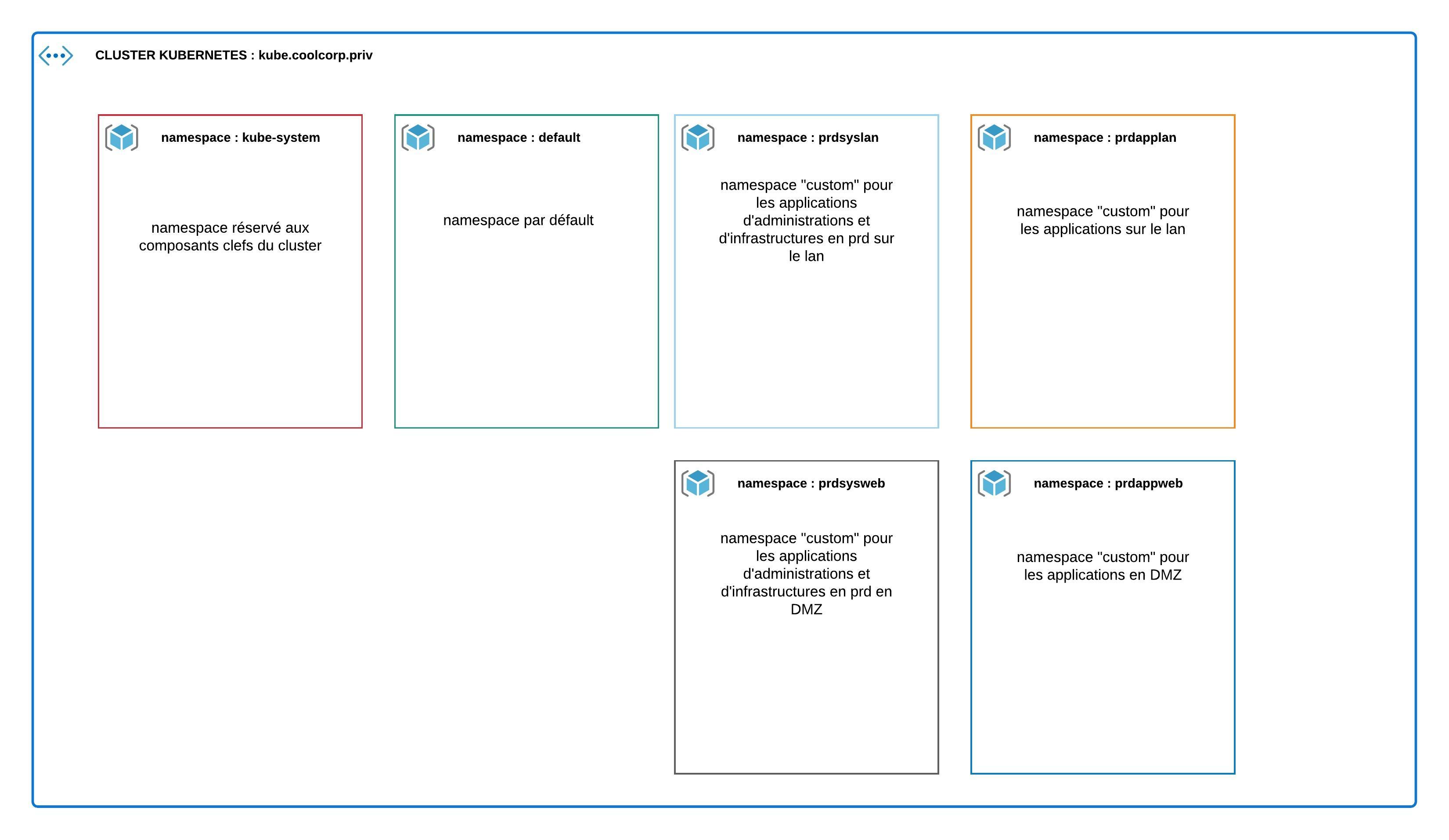
Je vérifie également que tous les pods dans le namespace "kube-system"
sont bien démarrés, en particulier les pod "coredns" avec la commande kubectl
get pod -n kube-system

Taches complémentaires
Label des nodes
La notion de label est très importante dans Kubernetes. Par défaut les noeuds master ont bien un label master mais les worker ne sont associé à aucun label pour leur role.
On va donc les marquer comme "worker". On va utiliser les commandes suivantes:
kubectl label nodes prdk8swok501 node-role.kubernetes.io/worker=kubectl label nodes prdk8swok502 node-role.kubernetes.io/worker=
kubectl label nodes prdk8swok503 node-role.kubernetes.io/worker=
kubectl label nodes prdk8swok504 node-role.kubernetes.io/worker=
kubectl label nodes prdk8swok505 node-role.kubernetes.io/worker=
kubectl label nodes prdk8swok511 node-role.kubernetes.io/worker=