Sauvegarder son infrastructure Kubernetes et ses applications
Introduction sur la sauvegarde sous Kubernetes
La sauvegarde est parfois un domaine laissé de côté. Pour certains « sauvegarder c’est douter »…
Pour moi, un backup opérationnel avec une procédure de restauration testée et validée est essentiel à toutes solutions en production.
J’ai pas mal galéré à trouver une démarche pour sauvegarder ce que je pouvais réaliser sur mon lab perso autour de Kubernetes.
On peut voir la sauvegarde de deux façons sous K8S (d’après moi):
- Une sauvegarde « applicative » : on s’appuie sur les stratégies de sauvegardes propres à l’application qui tourne sous format de pods. Par exemple, on peut réaliser des dumps pour des bases de données ou des exports de configurations pour certains outils, via script ou GUI. En déplaçant les données « statiques » sur un espace de stockage dédié on peut utiliser des outils de sauvegarde plus traditionnels pour sécuriser ces datas. L’avantage de ce type de backup, c’est d’être réalisable « nativement » et sans trop de difficulté. L’inconvénient concerne la rapidité de restauration, qui peut prendre un certain temps ou présenter une certaine complexité, car elle impose de restaurer composant par composant en s’assurant de la cohérence de chaque élément.
- Une sauvegarde « bas niveau » : on s’appuie sur une solution spécialisée qui va se charger de sauvegarder toutes les données liées au cluster Kubernetes. Une seule stratégie peut être suffisante pour sécuriser tout l’écosystème. L’avantage de cette solution est d’offrir une gestion centralisée de sa sauvegarde K8S et de pouvoir restaurer tout un ensemble d’applications en une seule opération. L’inconvénient est d’imposer et de dépendre d’une solution tierce. La mise en œuvre peut se montre également plus fastidieuse.
Pour moi l’idéal est de combiner les deux manières de faire. Plus on n’a de solutions pour restaurer sa donnée mieux c’est.
Présentation de velero
Cet article va plus particulièrement se focaliser sur une sauvegarde « bas niveau ». Si dans l’écosystème traditionnel des machines virtuelles, les solutions de backup ne manquent pas, je n’ai pas trouvé cette même richesse dans Kubernetes et surtout j’ai ressenti une maturité des outils proposés encore assez faible (ressenti personnel).
Sauvegarder ses ressources K8S n’est pas complexe en soi, car cela consiste en gros à sauvegarder ses fichiers YAML. C’est déjà plus compliqué avec des contraintes de données persistantes.
Pour cela, j’ai retenu la solution opensource velero. Elle permet de sauvegarder tous ses objets K8S incluant les volumes persistants.
Fonctionnement de velero
Pour fonctionner, velero installe ses propres composants au sein du cluster qu’il protège. velero va copier les éléments dans un « répertoire » de destination et va pouvoir s’appuyer sur des plug-ins tiers pour réaliser des « snaphots » des données.
Dans mon cas, je vais exploiter le plug-in vSphere, car mon petit lab tourne sous cet écosystème. Je vous invite d’ailleurs à suivre l' étape de déploiement de mon cluster K8S dans lequel j’ai intégré le driver CPI/CSI vmware. Le tutoriel suivant va donc s’appuyer sur cette logique, mais velero peut très bien s’utiliser sur d’autres infrastructures.
Ajout de minio
Comme « répertoire » de destination, le plug-in de snapshot vSphere velero impose l’usage d’un bucket S3. Je souhaite conserver mes données en local, je vais donc utiliser un autre outil , « minio » qui va me permettre de proposer un « bucket » sur mon infra locale compatible avec l’API S3.
La première partie du tutoriel va donc consister à déployer minio sur mon cluster Kubernetes.
Je vais utiliser pour cela les éléments suivants
|
01-nam-velero.yaml |
velero utilise par défaut un namespace dédié « velero ». Pour des questions de simplifications, je souhaite que minio tourne dans ce même namespace, j’anticipe donc sa création avec ce yaml |
|
02-dep-minio.yaml |
Fichier de déploiement de minio |
|
03-svc-minio.yaml |
Fichier de création du service associé à minio |
|
04-route-minio.yaml |
Fichier pour donner un accès à la GUI minio depuis traefik |
|
05-mid-redirecthttps-minio.yaml |
Fichier de redirection http vers https pour l'url de minio |
Création du namespace
Le contenu du fichier 01-nam-velero.yaml n’a rien de particulier
apiVersion: v1
kind: Namespace
metadata:
name: velero
J’applique le fichier
kubectl.exe apply -f 01-nam-velero.yaml
Création du secret
Avant d’aller plus loin, je vais créer un objet secret « sec-prd-minio » pour stocker la clef et son password permettant l’accès à minio et à son API
kubectl create secret generic sec-prd-minio --from-literal="access_key=ma_clef" --from-literal="secret_key=mon_password " --namespace=velero
Déploiement de minio
Je peux maintenant déployer minio via mon fichier 02-dep-minio.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dep-minio
namespace: velero
spec:
selector:
matchLabels:
app: minio
tiers: backup
replicas: 1
template:
metadata:
labels:
app: minio
tiers: backup
spec:
containers:
- name: minio
image: minio/minio
args:
- server
- /storage
env:
- name: MINIO_ACCESS_KEY
valueFrom:
secretKeyRef:
name: sec-prd-minio
key: access_key
- name: MINIO_SECRET_KEY
valueFrom:
secretKeyRef:
name: sec-prd-minio
key: secret_key
- name: MINIO_HTTP_TRACE
value: "/dev/stdout"
ports:
- containerPort: 9000
volumeMounts:
- name: storage
mountPath: "/storage"
volumes:
- name: storage
nfs:
path: /volume1/k8s-psv-nfs-rwm/minio/backup
server: storage.coolcorp.priv
readOnly: false
Le fichier me permet de déployer un pod dans lequel le conteneur minio va s’exécuter. Ce conteneur va mapper son dossier « storage » vers un partage NFS. Toutes mes images de sauvegarde vont donc pouvoir être hébergées à cet emplacement.
J’utilise le secret créé précédemment pour sécuriser l’accès à l’API minio via la rubrique env.
J’applique le fichier
kubectl.exe apply -f 02-dep-minio.yaml
Création du service
Je vais exposer l’API de minio et sa GUI au sein du cluster K8S à travers un service via le fichier 03-svc-minio.yaml
---
apiVersion: v1
kind: Service
metadata:
name: svc-minio
namespace: velero
spec:
type: LoadBalancer
ports:
- port: 9000
targetPort: 9000
protocol: TCP
selector:
app: minio
j’applique le fichier
kubectl.exe apply -f 03-svc-minio.yaml
Objet IngressRoute
J’utilise “traefik” pour gérer les accès extérieurs à mon cluster Kubernetes. Je vous invite à lire ma partie dédiée sur ce sujet pour bien comprendre son fonctionnement et son utilité.
Je créer donc un objet « ingressroute » via 04-route-minio.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: minio-http
namespace: velero
spec:
entryPoints:
- web
routes:
- kind: Rule
match: Host(`minio.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-minio
port: 9000
middlewares:
- name: https-redirectscheme
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: minio-https
namespace: velero
spec:
entryPoints:
- websecure
routes:
- kind: Rule
match: Host(`minio.inf.prd.k8s.coolcorp.priv`)
services:
- name: svc-minio
port: 9000
tls:
certResolver: le
j’applique le fichier
kubectl.exe apply -f 04-route-minio.yaml
Je vais maintenant pouvoir accéder à minio via l’URL minio.inf.prd.k8s.coolcorp.priv.
Afin d’avoir une redirection automatique vers https, il ne me reste plus qu’a créer un objet middlerware via le fichier « 05-mid-redirecthttps-minio.yaml »
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: https-redirectscheme
namespace: velero
spec:
redirectScheme:
scheme: https
permanent: true
j’applique le fichier
kubectl.exe apply -f 05-mid-redirecthttps-minio.yaml
minio est maintenant accessible depuis mon poste de travail et l’url https://minio.inf.prd.k8s.coolcorp.priv
Je m’authentifie avec ma clef et mon password.
Je crée un bucket que je nomme K8S.

Minio est maintenant prêt pour être utilisé avec velero
Déploiement de velero
Installation
J’ai choisi d’utiliser la méthode d’installation à partir du binaire velero directement téléchargé sur mon poste de travail sous Windows 10.
Une fois le binaire récupéré, je prépare le fichier « credentials-velero.yaml » qui va contenir les éléments de configuration pour l’accès à minio
[default]
aws_access_key_id = ma_clef
aws_secret_access_key = mon_password
Il s’agit des mêmes éléments d’authentification que j’ai utilisés dans mon objet secret kubernetes lors du déploiement de minio.
Il ne me reste plus qu’à lancer l’installation de velero. (Bien entendu cela nécessite que mon poste de travail dispose de la configuration d’accès à mon cluster kubernetes. Je vous invite pour cela à lire mon article sur le déploiement de mon cluster K8S).
La ligne d’installation de velero est assez parlante.
velero install --provider aws --plugins velero/velero-plugin-for-aws:v1.0.1 --bucket k8s --secret-file credentials-velero.yaml --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://svc-minio:9000,publicUrl=https://minio.inf.prd.k8s.coolcorp.priv
Elle va déployer les objets Kubernetes propres à velero au sein de mon cluster en incluant le plug-in AWS. Celui-ci va être paramétré pour accéder à mon bucket K8S créer sur minio. Il faut donc fournir deux URL :
- L’URL interne à kubernetes qui correspond à mon service associé à mon pod minio : http://svc-minio:9000
- L’URL externe gérée par traefik et qui redirige vers le service minio : https://minio.inf.prd.k8s.coolcorp.priv
Les droits d’accès se font grâce au fichier « credentials-velero.yaml » passé en argument de la commande
Je vérifie le bon déploiement de velero avec la commande
kubectl logs deployment/velero -n velero

Déploiement du plug-in vsphere pour velero
Je peux maintenant procéder à l’installation du plug-in vsphere pour velero dont les instructions d’installation sont disponibles ici
La commande de déploiement est la suivante
velero plug-in add vsphereveleroplugin/velero-plugin-for-vsphere:1.0.0
À noter un élément très important. À la date de rédaction de cet article, j’ai rencontré un bug référencé dans la FAQ du plug-in Il faut absolument que les VMs kubernetes soient à la racine du cluster vsphere. Il ne faut pas utiliser de dossier (chose que j’avais faite au départ), sinon les restaurations échouent.
Une fois le plug-in déployé, je crée l’objet « VolumeSnaphotLocation ». Celui-ci ne correspond pas à un stockage réel, mais permet l’appel du plug-in.
velero snapshot-location create vsl-vsphere --provider velero.io/vsphere
Arriver à cette étape, j’ai dans mon namespace velero 4 pods
- 1 pod minio pour l’hébergement des images de sauvegardes via un bucket « S3 compatible »
- 1 pod velero pour la gestion de la solution de sauvegade velero
- 2 pods datamgr-for-vsphere-plugin (1 par worker) liés à l’usage du plug-in vsphere.

Création d'une sauvegarde
Je créé une première sauvegarde en désignant par exemple comme source, tous les éléments d’un namespace « test »
velero backup create test01-backup --include-namespaces=test --snapshot-volumes --volume-snapshot-locations vsl-vsphere
Je surveille l’état de la sauvegarde via la commande
velero backup describe test01-backup –detail
Une fois la sauvegarde terminée, cette commande me retourne toutes les informations sur les éléments traités. On y retrouve la liste des objets kubernetes ainsi que l’identifiant du snaphot utilisé pour sauvegarder le volume persistant qui se trouve dans ce namespace.
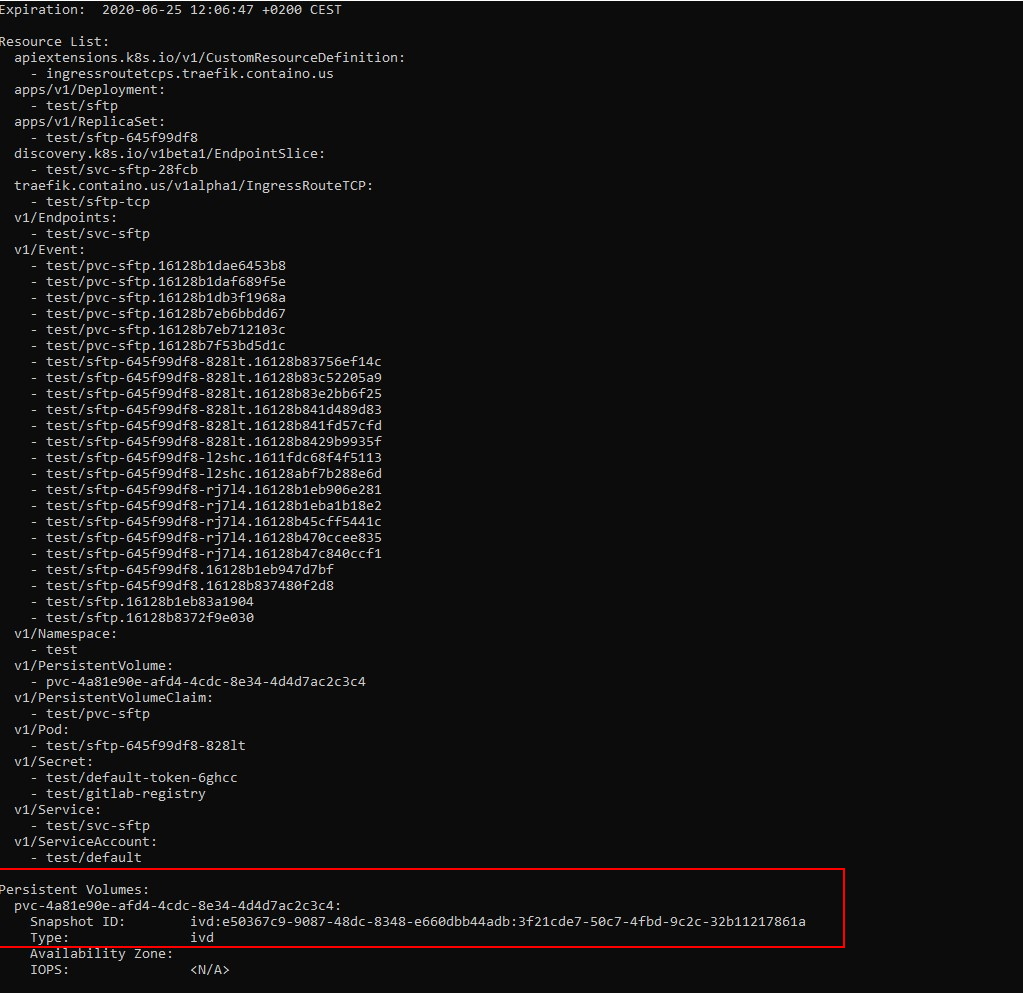
Attention, ce n’est pas parce que cette commande retourne un état « terminé » que la sauvegarde l’est réellement. Il se peut que les datas soient toujours en cours d’upload sur le bucket.
Pour être certains que le backup soit terminé, il faut utilisé la commande suivant
kubectl get -n velero uploads.veleroplugin.io -o yaml
On recherche l’identifiant du snapshot et on vérifie que le statut d’upload des données qui lui sont associés soit bien "completed"
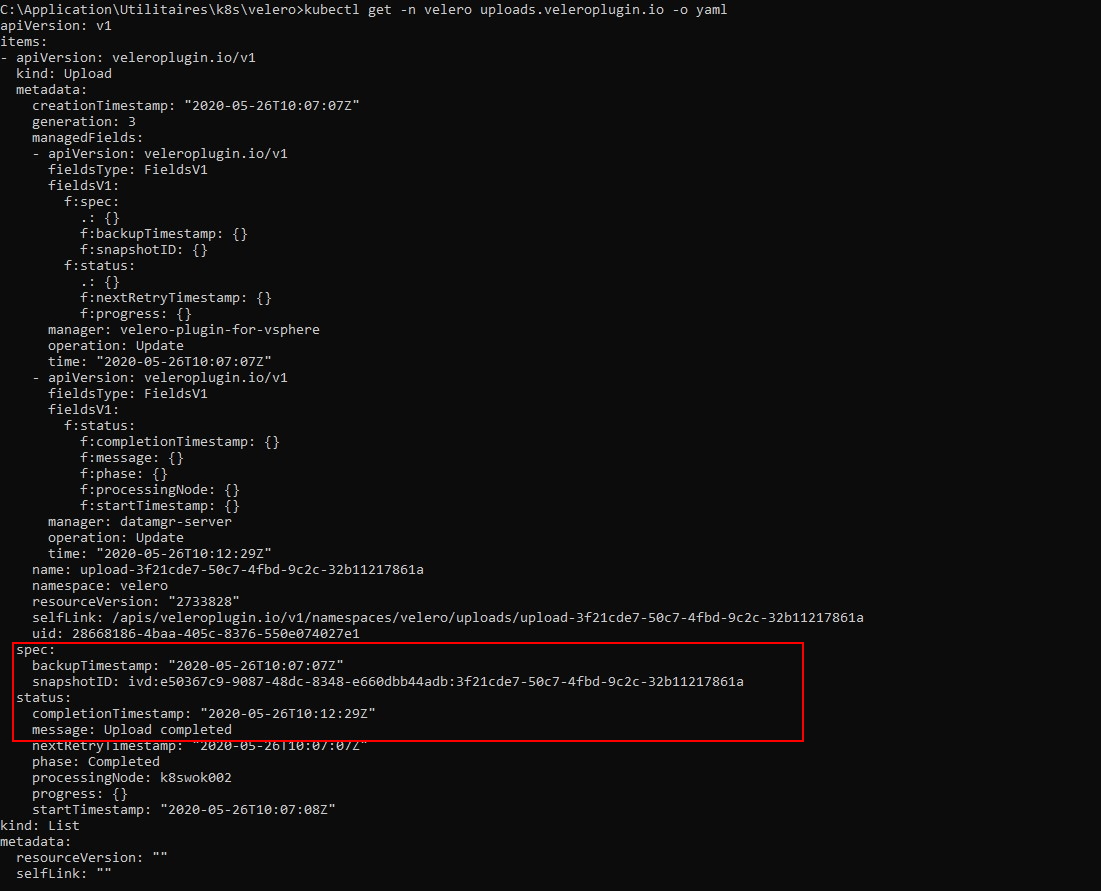
On n’est maintenant sûre que la sauvegarde est complète.
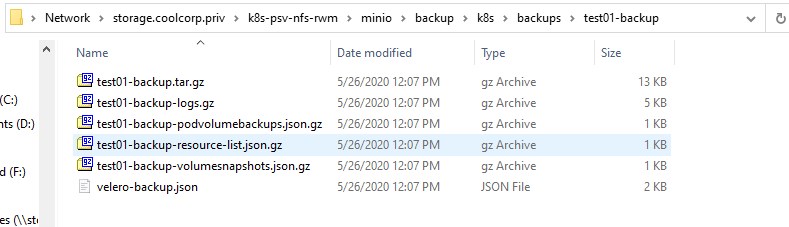
J’accède maintenant au partage NFS « caché » derrière mon bucket « S3 » compatible, j’ai bien un répertoire correspondant à ma sauvegarde qui a été créé avec les objets Kubernetes.
Test d'une restauration
Je détruis maintenant tous les objets dans mon namespace test pour ensuite lancer une restauration via la commande
velero restore create --from-backup test01-backup
Je vérifie l’état de la restauration avec la commande
velero restore describe test01-backup-20200526122226 –details
À la fin de l’opération, tous mes objets Kubernets ont été restaurés incluant les données de mon volume persistant.
Conclusion
J’ai réalisé plusieurs tests, et j’ai parfois rencontré des incidents à la restauration.
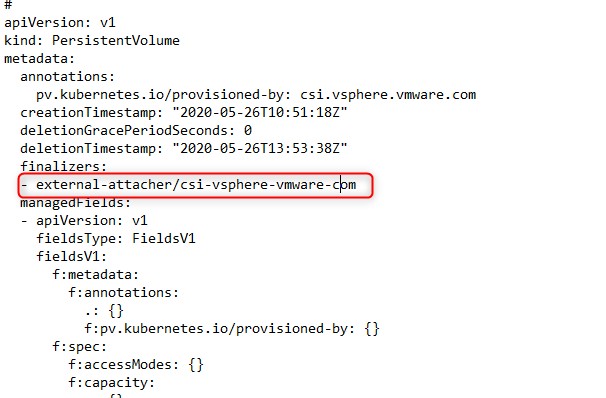
- Refus de restaurer le volume persistent.
Ce problème était lié au fait que mon volume était resté en statut « terminating » lorsque j’ai détruit tous les objets de mon namespace tests avant la restauration. J’ai plusieurs fois rencontré ce problème avec le driver CSI vsphere. Il peut parfois s’avérer que le volume que l’on a demandé à supprimer reste dans un statut « terminating ». Cela semble être un bug avec la version actuelle du driver CSI sous vsphere 6.7.
Pour forcer sa suppression, il faut éditer directement l'objet avec la commande kubectl edit pv nom_du_pv et supprimer les références présentes dans la section "finalizers"
- Le pod ne veut pas redémarrer après sa restauration, indiquant qu’un volume persistant n’est pas disponible.
Ce problème semble lié à la non-disponibilité du volume lors de la restauration du pod. Il suffit alors de supprimer le déploiement associé au pod et de le recréer à partir du fichier yaml qui a été utilisé pour le générer (d’où l’important d’avoir plusieurs sources de sauvegarde)
Velero est extrêmement puissant, on peut planifier ses sauvegardes, configurer ses rétentions, filter les objets à sauvegarder. Il peut également être utilisé pour migrer d’une infrastructure Kubernetes à une autre. J’ai simplement pu constater qu’en l’état avec le plug-in vsphere, la stabilité n’est pas encore formidable, obligeant parfois à procéder à des manipulations posts opérations de restaurations. Mais désormais, en sauvegardant mes fichiers yaml, en réalisant des dumps de mes bases, je bénéficie en plus d’une solution de sauvegarde bas niveau me permettant de très rapidement rétablir tout un écosystème sur mon cluster K8S.