Superviser son cluster Kubernetes
Introduction sur la supervision et sa mise en oeuvre pour K8S
Généralité sur la supervision
La supervision est pour moi un élément clef d’une architecture. Tout système en production (et pas que) doit pouvoir être monitoré de manière à détecter, voir à anticiper les incidents. C’est très à la mode de parler désormais d’ « observabilité » plutôt que de supervision. L’idée étant de ne plus se contenter des classiques charge mémoire et CPU mais d’avoir une parfaite lisibilité des composants d’une application. C’est à cette dernière d’exposer ses propres métriques et d’indiquer son état (la supervision doit donc être pensée dès le développement). Ce fonctionnement nécessite des outils adaptés qui parfois s’éloignent des solutions de supervision traditionnelle (ce qui ne peut pas dire qu'elles ne sont plus légitimes ou nécessaires).
Prometheus est devenu un standard pour traiter ce genre de problématique. Il « découvre » et « scanne » les métriques exposées pour permettre leur consultation depuis un langage de requêtage adapté. Le plus souvent il est complété de « grafana », l’application phare pour la création de dashboard et de graphiques.
L’idée de cet article n’est pas de rentrer dans le détail de ces outils, vous trouverez de nombreux articles sur leur fonctionnement et leur mise en œuvre. J’ai plutôt comme objectif de traiter des éléments à mettre en œuvre pour qu’il puisse être utilisé avec Kubernetes, de manière à avoir une parfaite « observabilité » d’un cluster K8S.
La supervision dans Kubernetes
Le web regorge de tutoriels permettant un déploiement en quelques minutes d’un « kit » de supervision intégrant les applications citées précédemment directement adaptées à Kubernetes. Si cela s’avère très pratique, j’ai quelques problématiques à les utiliser. Dans un premier temps, si je peux obtenir une solution opérationnelle très rapidement, j’en apprends très peu sur la mise en œuvre puisqu’elle est déjà réalisée pour moi. (même si tous les fichiers de configuration et codes utilisés sont visibles si nécessaire). Le point le plus critique étant que ces tutoraux partent du principe que c’est le cluster Kubernetes lui-même qui est utilisé pour faire tourner les outils de supervision. La plupart du temps lorsqu’on évoque Prometheus avec K8S, on admet que celui-ci tourne sur le cluster qu’il monitor.
Chacun son avis, mais personnellement, je suis assez ancienne école en considérant que la brique de supervision (ou observabilité :😊) ne doit pas s’exécuter dans la mesure du possible sur l’architecture qu’elle est censé traiter. Si un problème survient sur cette architecture et que la supervision s’en trouve impactée, il devient alors difficile d’avoir accès à des métriques pouvant aider à la résolution de l’incident. C’est pourquoi je préfère monitorer mon cluster Kubernetes depuis une instance prometheus externe à ce dernier. J’ai à ce moment eu beaucoup plus de mal trouver des exemples pouvant couvrir cette logique.
Je vais donc essayer de m’attarder dans cet article les points suivants :
- Activation et exposition des métriques kubernetes
- Activation et exposition des métriques dans traefik
- Exposition des métriques velero
- Intégration de ces métriques dans une instance prometheus externe.
Mise en place de metrics-server
Kubernetes dispose de différents moyens pour fournir des métriques. Toujours dans cette logique de décomposition des fonctions, K8S laisse cette charge à différents modules activables ou non.
Je vais donc tout d’abord installer « metric-server ». Ce composant permet d'obtenir des données de monitoring depuis l'API Kubernetes.
Je récupère pour cela le yaml de déploiement fourni sur le repot git.
---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: system:aggregated-metrics-readerlabels:rbac.authorization.k8s.io/aggregate-to-view: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-admin: "true"rules:- apiGroups: ["metrics.k8s.io"]resources: ["pods", "nodes"]verbs: ["get", "list", "watch"]---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: metrics-server:system:auth-delegatorroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegatorsubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata:name: metrics-server-auth-readernamespace: kube-systemroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-readersubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system---apiVersion: apiregistration.k8s.io/v1beta1kind: APIServicemetadata:name: v1beta1.metrics.k8s.iospec:service:name: metrics-servernamespace: kube-systemgroup: metrics.k8s.ioversion: v1beta1insecureSkipTLSVerify: truegroupPriorityMinimum: 100versionPriority: 100---apiVersion: v1kind: ServiceAccountmetadata:name: metrics-servernamespace: kube-system---apiVersion: apps/v1kind: Deploymentmetadata:name: metrics-servernamespace: kube-systemlabels:k8s-app: metrics-serverspec:selector:matchLabels:k8s-app: metrics-servertemplate:metadata:name: metrics-serverlabels:k8s-app: metrics-serverspec:serviceAccountName: metrics-servervolumes:# mount in tmp so we can safely use from-scratch images and/or read-only containers- name: tmp-diremptyDir: {}containers:- name: metrics-serverimage: k8s.gcr.io/metrics-server-amd64:v0.3.6imagePullPolicy: IfNotPresentargs:- --cert-dir=/tmp- --secure-port=4443- --kubelet-insecure-tlsports:- name: main-portcontainerPort: 4443protocol: TCPsecurityContext:readOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000volumeMounts:- name: tmp-dirmountPath: /tmpnodeSelector:kubernetes.io/os: linuxkubernetes.io/arch: "amd64"---apiVersion: v1kind: Servicemetadata:name: metrics-servernamespace: kube-systemlabels:kubernetes.io/name: "Metrics-server"kubernetes.io/cluster-service: "true"spec:selector:k8s-app: metrics-serverports:- port: 443protocol: TCPtargetPort: main-port---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: system:metrics-serverrules:- apiGroups:- ""resources:- pods- nodes- nodes/stats- namespaces- configmapsverbs:- get- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: system:metrics-serverroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-serversubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system
J'ajoute simplement l’option - --kubelet-insecure-tls dans les variables envs pour ne pas poser problème avec les certificats autogénérés lors du déploiement de mon serveur K8S.
kubectl deploy -f components.yaml
Je peux maintenant utiliser la commande « kubectl top » pour obtenir des statistiques sur mes nodes ou mes pods.
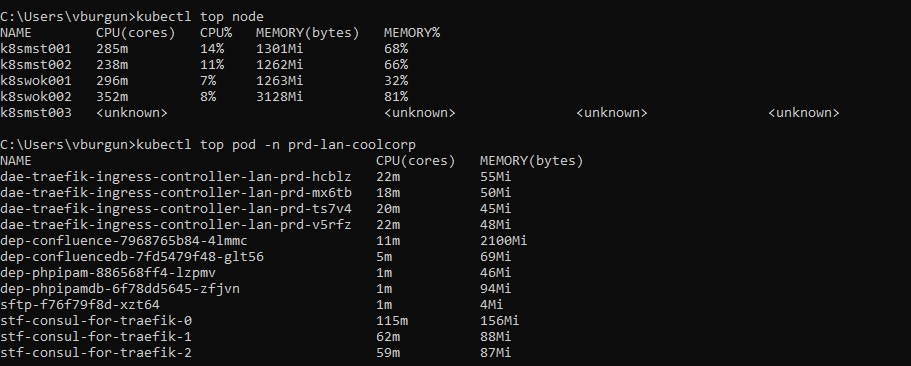
Création d'un compte de services K8S pour la supervision
Avant de poursuivre sur prometheus. Je vais d’abord créer un compte de service dédié à la supervision avec des droits d’accès en lecture uniquement à mon cluster.
Création d'un namespace
Je crée un namespace « supervision » avec le fichier 01-nam-supervision.yaml
apiVersion: v1
kind: Namespace
metadata:
name: supervision
kubectl apply -f 01-nam-supervision.yaml
Création d'un compte de service
Je crée mon compte de service « service-supervision » dans mon namespace « supervision » via le fichier 02-sup-service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: service-supervision
namespace: supervision
kubectl apply -f 02-sup-service-account.yaml
Création du role pour la supervision
J’utilise maintenant un fichier 03-sup-rbac.yaml pour créer mon role spécifique en lecture seul sur toutes les ressources de mon cluster.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
namespace: supervision
name: supervision
rules:
- apiGroups: [""]
resources: ["*"]
verbs: ["get", "watch", "list"]
- apiGroups: ["extensions"]
resources: ["*"]
verbs: ["get", "watch", "list"]
- apiGroups: ["apps"]
resources: ["*"]
verbs: ["get", "watch", "list"]
Je fais appel à un objet « clusterrole », qui indique que les droits que je déclare s’appliquent à tous le cluster et sont transverses aux namespaces.
Je ne déclare que les droits « get », « watch » et « list ».
kubectl apply -f 03-sup-rbac.yaml
Il ne me reste plus qu’à associer ce role à mon compte de service via le fichier « 04-clusmapping.yaml »
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: crb-service-supevision
namespace: supervision
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: supervision
subjects:
- kind: ServiceAccount
name: service-supervision
namespace: supervision
kubectl apply -f 04-clusmapping.yaml
Récupération du token du compte de service
J’ai désormais un compte de service « service-supervision » avec les droits en lecture seul sur mon cluster.
Je récupère son token via la commande powershell
kubectl -n supervision describe secret $(kubectl -n supervision get secret | sls service-supervision | ForEach-Object { $_ -Split '\s+' } | Select -First 1)

Ce token va me permettre de m’authentifier depuis prometheus.
Configuration dans prometheus
Comme déjà évoqué, je ne vais pas expliquer l’installation de prometheus. Dans mon cas, je l’ai déployé sur une VM Ubuntu 20.04. Au moment de la rédaction de cet article, c’est la version 2.18 que j’utilise qui, nativement , peut échanger avec Kubernetes.
Configuration pour l'accès aux métriques Kubernetes
Voici mon fichier de configuration prometheus
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
insecure_skip_verify: true
ca_file: /etc/prometheus/ca_k8s.crt
bearer_token: "eyJhbGciOiJSUzI1NiIsImtpZCI6IjNpcmt0OGZtdi16c2tPT291YUE0YzZUb0hsaTFTQ3UwN0wtN2tGcjBvSW8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJzdXBlcnZpc2lvbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJzZXJ2aWNlLXN1cGVydmlzaW9uLXRva2VuLWs1OWpqIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6InNlcnZpY2Utc3VwZXJ2aXNpb24iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmNTVmOTUwZS1iMjY0LTRlZmMtYWY5Ny1kY2FkMDE1MTBhMzUiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6c3VwZXJ2aXNpb246c2VydmljZS1zdXBlcnZpc2lvbiJ9.TlKApKhiCzj8n7b_70gxvElU4eObLoU3m75dEOWniHAJdfunGbqdQp33qjE5EfNO7IKFVg5UKJBVipsC8RosDEYzlJJA3xsFXBC3AdY-UOW6UYLTJzcMAqtiYkXv9wKd6OAcck208LWxbYkH12gg0oSC0hkqmRY3H20e6Fc7jCc6I0yCWdHp4_rRMbOgdjMLXKFQ7le-mNz2Zx3Xq4fsa9FzfPaDXivUjvpwaLhG22sGD1gWa8iTtD5-wVyIjAefMTM-nh0lzfnMybfUcnKqcl8a0Xrzw924AVZ68cgZWFhoJx5PbJEe0KrPnY1TIKHRzXHpwhOQjKxoOB6ZAOLAdw"
kubernetes_sd_configs:
- role: node
api_server: https://kube.coolcorp.priv:6443
tls_config:
insecure_skip_verify: true
ca_file: /etc/prometheus/ca_k8s.crt
bearer_token: "eyJhbGciOiJSUzI1NiIsImtpZCI6IjNpcmt0OGZtdi16c2tPT291YUE0YzZUb0hsaTFTQ3UwN0wtN2tGcjBvSW8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJzdXBlcnZpc2lvbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJzZXJ2aWNlLXN1cGVydmlzaW9uLXRva2VuLWs1OWpqIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6InNlcnZpY2Utc3VwZXJ2aXNpb24iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmNTVmOTUwZS1iMjY0LTRlZmMtYWY5Ny1kY2FkMDE1MTBhMzUiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6c3VwZXJ2aXNpb246c2VydmljZS1zdXBlcnZpc2lvbiJ9.TlKApKhiCzj8n7b_70gxvElU4eObLoU3m75dEOWniHAJdfunGbqdQp33qjE5EfNO7IKFVg5UKJBVipsC8RosDEYzlJJA3xsFXBC3AdY-UOW6UYLTJzcMAqtiYkXv9wKd6OAcck208LWxbYkH12gg0oSC0hkqmRY3H20e6Fc7jCc6I0yCWdHp4_rRMbOgdjMLXKFQ7le-mNz2Zx3Xq4fsa9FzfPaDXivUjvpwaLhG22sGD1gWa8iTtD5-wVyIjAefMTM-nh0lzfnMybfUcnKqcl8a0Xrzw924AVZ68cgZWFhoJx5PbJEe0KrPnY1TIKHRzXHpwhOQjKxoOB6ZAOLAdw"
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kube.coolcorp.priv:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
La partie qui nous intéresse est en rouge. Elle définit le job de découverte des métrics que j’ai appelés 'kubernetes-nodes'. J’applique une configuration globale qui précise
- de faire confiance à tous certificats (insecure_skip_verify: true),
- d’utiliser comme certificat root (public bien sûr) celui associé à mon cluster kubernetes (récupérable dans /etc/kubernetes/pki/ sur l’un des nœuds master).
- d'utiliser mon token (bearer_token) correspondant à mon compte de service pour s'authentifier auprès du cluster. Je précise qu’il est possible pour plus de sécurité d’utiliser une authentification par certificat à la place du token.
J’en arrive maintenant à la configuration spécifique kubernetes via la section kubernetes_sd_configs
C’est ce mot clef qui va indiquer à Prometheus qu’il va s’adresser à un cluster kubernetes. Je répète les arguments précédents (très important) et je précise l’adresse de l’API de mon cluster (kube.coolcorp.priv :6443) qui correspond à une ip vituelle gérée par un load balancer HAproxy qui renvoie vers mes master. Je vous invite à lire la partie traitant du déploiement du cluster K8S sur mon lab perso pour plus de détails.
Le reste de la configuration est issue de la doc Prometheus sur le sujet. Si on creuse un peu, prometheus va s’adresser à la couche API de K8S pour récupérer les métriques via la couche metric-server que j’ai déployé précédemment.
De plus, on va pouvoir obtenir des statistiques internes à chaque pod et à chaque conteneur, ceci grâce à cadvisor. C’est un outil développé par Google et intégré désormais à chaque « kubelet ». (« Kubelet » étant l’agent Kubernetes présent sur chaque nœud du cluster).
Dans cette configuration, prometheus ne discute qu’avec la couche API de kubernetes et jamais directement avec ces agents kubelet. À noter qu’à partir d’une certaine version de K8S, les métriques propres à cadvisor sont interrogeables à l’URL /api/v1/nodes/nom_du_noeud/proxy/metrics/cadvisor et non plus directement à la racine de metrics, ce qui explique les règles de replacement incluses dans cette exemple.
Récupération des métriques Traefik
Comme expliqué dans la partie dédié du déploiement de mon cluster K8S sur ce sujet, j’utilise Traefik comme moteur ingress pour les accès externes. Il s’avère que ce dernier peut également exposer des métriques à Kubernetes. Pour cela il me suffit d’ajouter les éléments de configuration suivants dans le yaml de déploiement (voir le fichier 05-das-traefik-ingress-controller.yaml dans la partie sur Traefik)
- --metrics.prometheus.addEntryPointsLabels=true
- --entryPoints.metrics.address=:8082
- --metrics.prometheus.entryPoint=metrics
Bien entendu il me faut mettre également à jour ma configuration HAProxy (voir présentation de l'architecture)
frontend kub_traefik_metric
bind *:8082
option tcplog
mode tcp
default_backend kube_traefik_me
backend kube_traefik_met
mode tcp
balance roundrobin
option tcp-check
server k8smst001 192.168.10.70:8082 check
server k8smst002 192.168.10.71:8082 check
server k8Smst003 192.168.10.72:8082 check
Concernant Prometheus il me suffit d’ajouter la configuration suivante
- job_name: 'traefik'
scrape_interval: 5s
static_configs:
- targets: ['kube.coolcorp.priv:8082']
Exposition des métriques véléro
Enfin, je termine par la partie velero. Je vous invite à lire l’article qui traite de cette solution de sauvegarde pour Kubernetes. Cette dernière peut également exposer des métrics à prometheus.
C’est le cas par défaut lorsqu’on déploie velero. Il faut par contre les rendre accessibles depuis l’extérieur du cluster (dans mon cas). J’utilise traefik pour cela en ajoutant des objets spécifiques pour pour publier une route sur le port « 8085 » (port par défaut ou velero expose ses métriques).
Je crée d’abord un objet service via le fichier "01-svc-velero.yaml"
apiVersion: v1
kind: Service
metadata:
name: svc-velero
namespace: velero
spec:
selector:
component: velero
ports:
- name: velero
protocol: TCP
port: 8085
targetPort: 8085
kubetcl apply -f 01-svc-velero.yaml
Puis je crée la route traefik via le fichier 02-rot-velero.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRouteTCP
metadata:
name: velero-tcp
namespace: velero
spec:
entryPoints:
- velero
routes:
- kind: Rule
match: HostSNI(`*`)
services:
- name: svc-velero
port: 8085
kubectl apply -f 02-rot-velero.yaml
J’ai donc maintenant une publication des métriques velero sur le port 8085 via traefik.
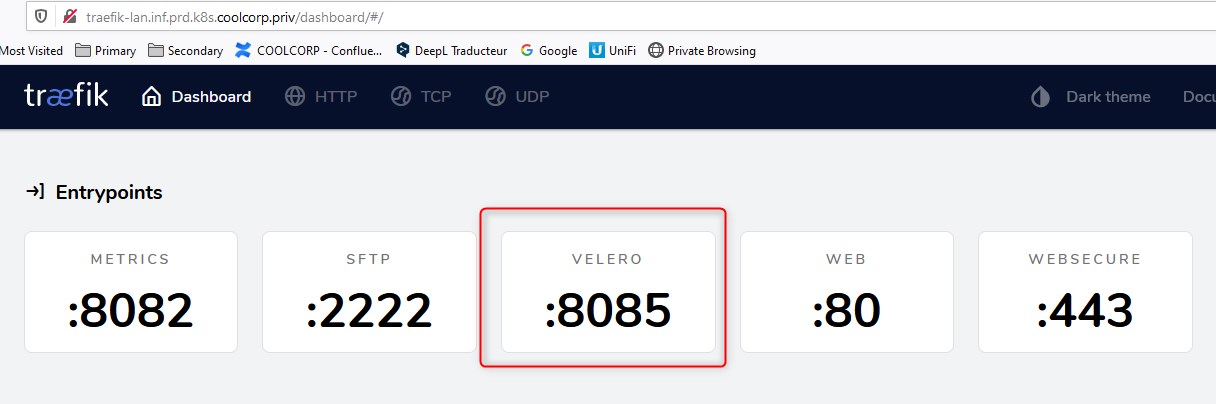
Il me suffit de mettre à jour ma configuration HAproxy (voir partie présentation architecture)
frontend kub_velero_metric
bind *:8085
option tcplog
mode tcp
default_backend kube_velero
backend kube_velero
mode tcp
balance roundrobin
option tcp-check
server k8smst001 192.168.10.70:8085 check
server k8smst002 192.168.10.71:8085 check
server k8Smst003 192.168.10.72:8085 check
Dans Prometheus j’ai juste à ajouter la configuration suivante:
- job_name: 'velero'
static_configs:
- targets: ['velero.inf.prd.k8s.coolcorp.priv:8085']
(L’adresse 'velero.inf.prd.k8s.coolcorp.priv” pointe vers ma VIP HAproxy via un alias DNS)
Vérifications et résultats
Si maintenant je vérifie les target via la GUI de prometheus, je retrouve les résultats suivants
- Kubernetes
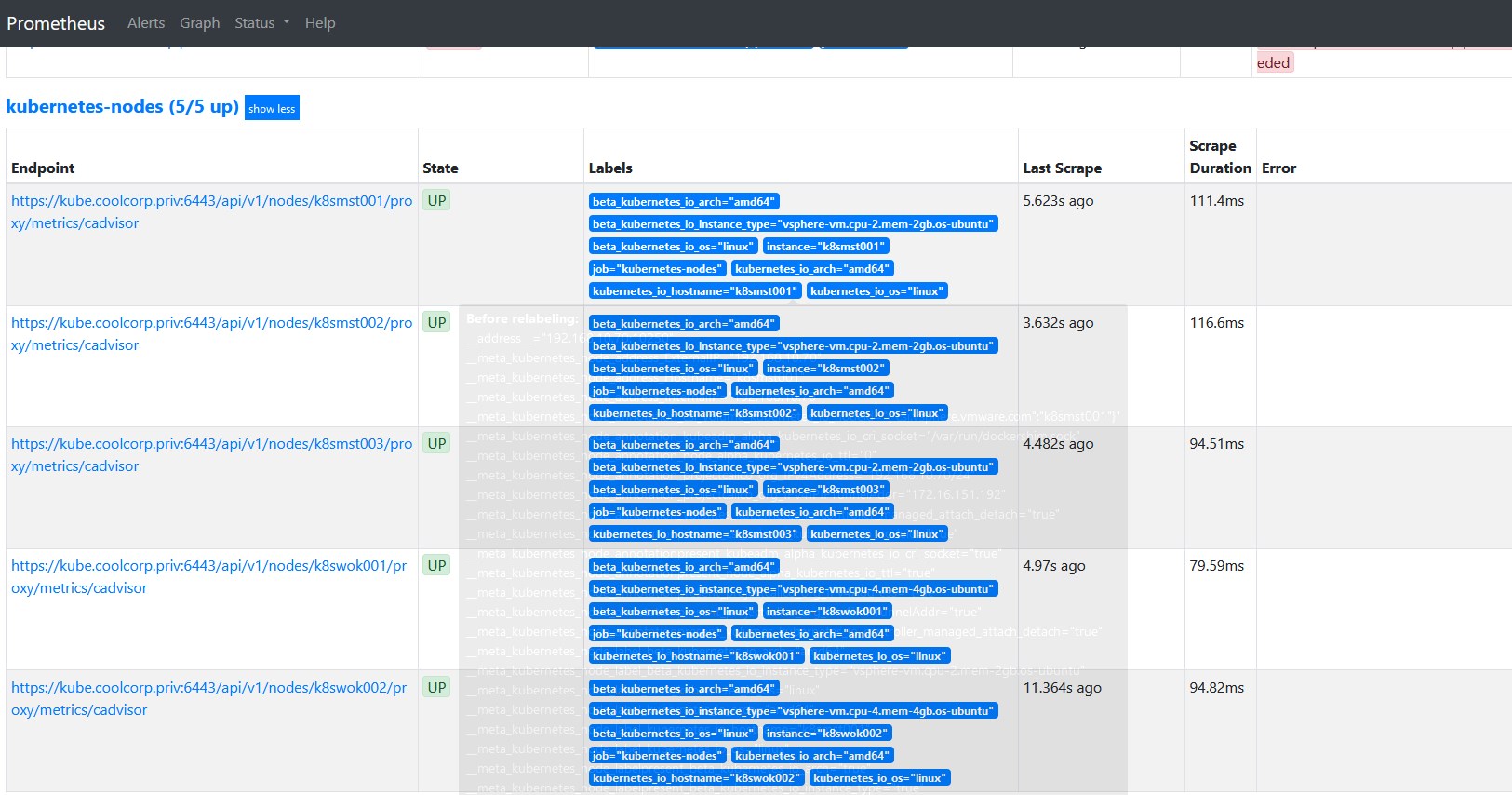
- Traefik

- Velero

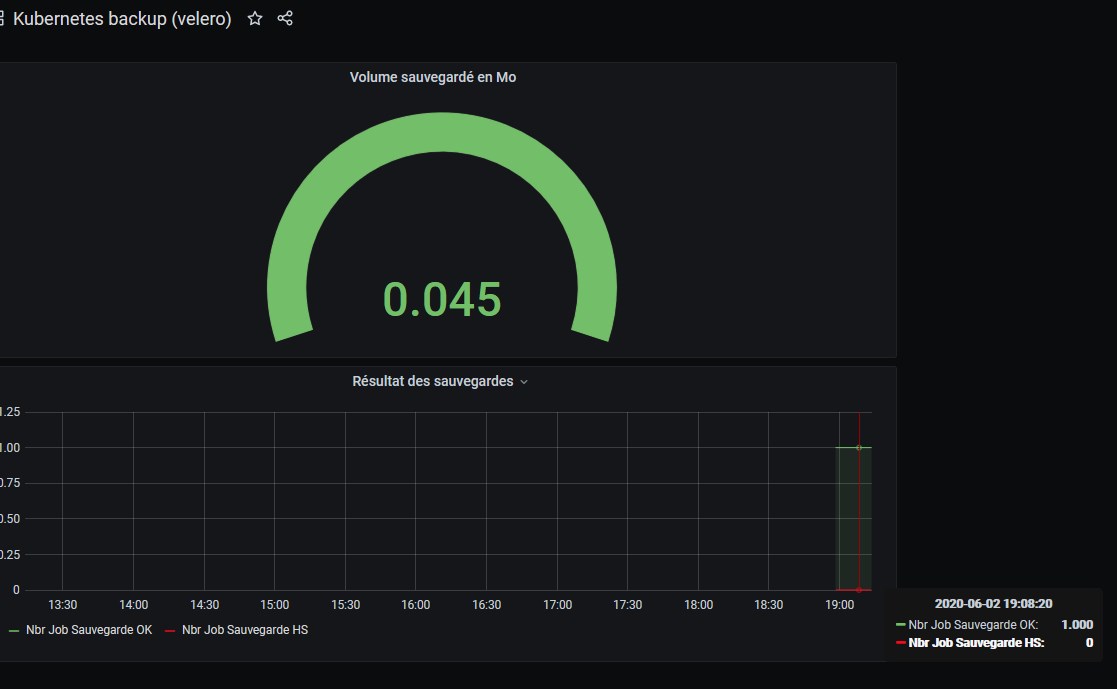
Exemple de dashboards
Prometheus dispose désormais de nombreuses valeurs propres à mon environnement Kuberntes.
Je peux désormais utiliser grafana pour mettre en valeur ces données.
Par exemple via les d’abord fournit par la communauté
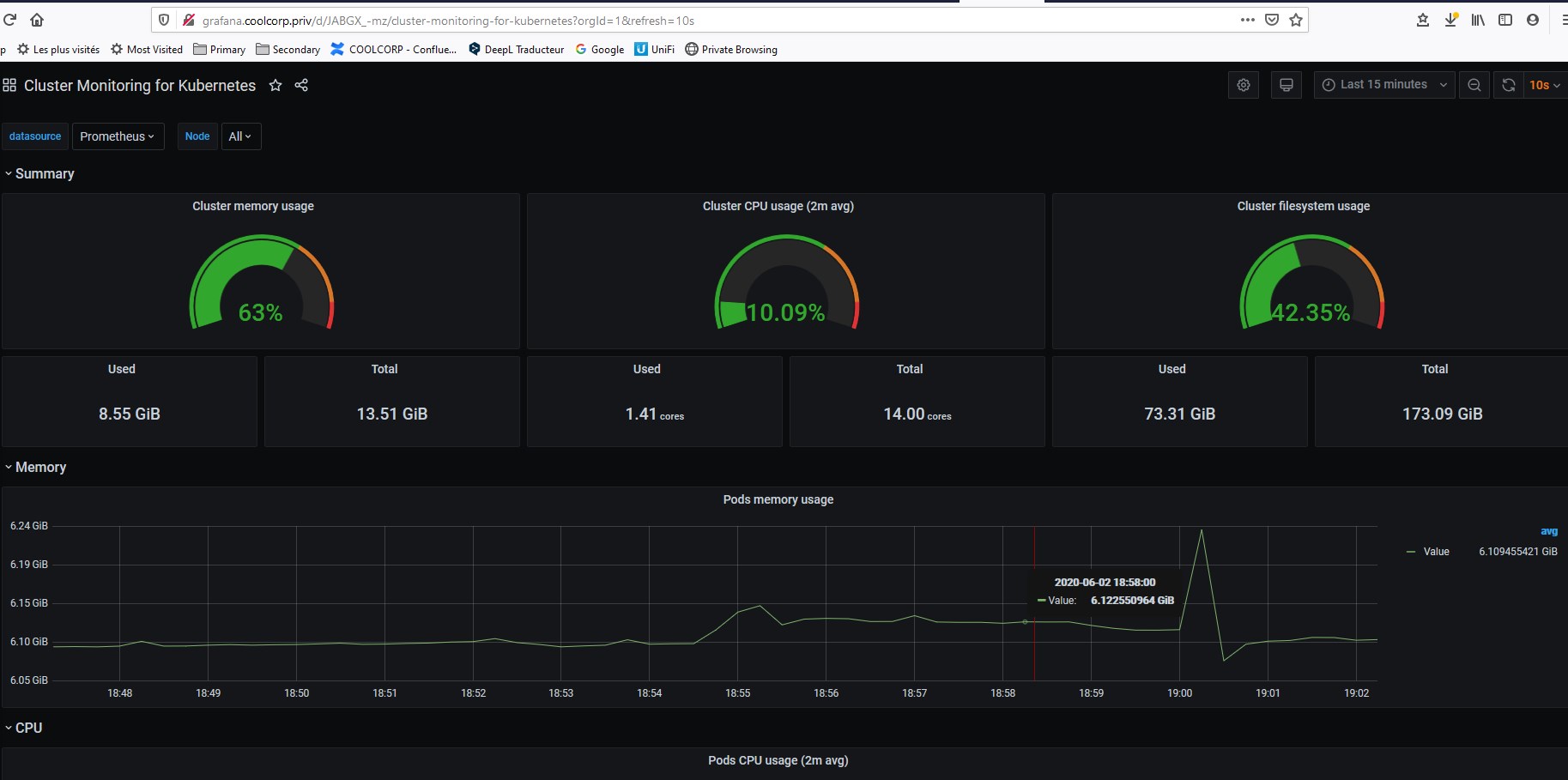
Ou bien en créant ses propres dashboards à partir des valeurs qui nous intéressent.
Conclusion
Je découvre Prometheus et grafana depuis peu au moment de la rédaction de cet article. Il est évident qu’une fois les métriques accumulées, un gros travail est nécessaire pour construire sa supervision (quoi surveiller ? quoi mettre en avant ?) et mettre en place les bons seuils d’alertes. Ce n’est pas le but ici, l’idée était simplement de mettre en œuvre les éléments nécessaires pour superviser son cluster Kubernetes.